Question # 4
An administrator configures disaster recovery between an on-premises AZ and a Nutanix Cloud AZ. After enabling DR and assigning protection policies to several VMs with volume groups, the administrator initiates failover and notices the VMs do not have their volume groups attached. Investigation reveals:
The clusters are successfully paired in Prism Central.
Protection policies and replication schedules are configured correctly.
Recovery plan validation completes successfully.
Required firewall ports between sites are confirmed open.
Management IP addresses are reachable in both directions.
Despite this, the administrator observes the volume groups are still not attached. Which network-related prerequisite is most likely misconfigured?
Question # 5
Exhibit:
An administrator wants to protect the snapshots created on the cluster. Only authorized users should be allowed to modify or delete the snapshots on the cluster. How can the administrator harden the security of the snapshots?
Question # 6
A Nutanix protection policy is configured with:
RPO: 1 hour,
Retention period: 5 days,
Retention type: Roll-up.
After six days of continuous operation, approximately how many hourly recovery points will still be available for restores for the most recent 24-hour period?
Question # 7
An administrator intends to configure a NearSync replication schedule with a 15-minute Recovery Point Objective (RPO) on a hybrid 3-node cluster. The current nodes in the cluster are configured with one SSD and four HDDs each. Which cost-effective modification is required to support this specific replication schedule?
Question # 8
An administrator has been tasked with configuring a Nutanix replication solution that provides an RPO of zero. Which solution should the administrator choose?
Question # 9
An administrator is validating a newly created Recovery Plan and receives the following warning:
IP addresses xxx.xxx.xxx.xxx cannot be preserved/mapped for VM REPORTVM01.
IP addresses cannot be preserved/mapped for entities
IP might be already in use or will be used by some other VM for recovery. IP cannot be mapped.
Only one IP address can be preserved for a vNIC in an IP address management enabled network.
What can the administrator do to resolve this warning without changing the existing IP address assigned to the VM?
Question # 10
An administrator plans to migrate guest VMs from a legacy Protection Domain–based DR plan to the Prism Central–based Disaster Recovery solution. What should be done first before removing the legacy protection domains?
Question # 11
A VM is configured with a 5-minute Nearsync RPO. After several hours, replication transitions back to hourly RPO. Alerts indicate the minute schedule cannot be maintained. What is the most likely root cause?
Question # 12
An administrator has VMs in a container named VMData on Cluster A that need to be replicated to Cluster B. In order to configure new replications to Cluster B, the administrator creates a container named VMData on Cluster B with an advertised capacity of 200GB.
The VMs on Cluster A in the VMData container have these characteristics:
Large VMs taking up 4TB of space
Low data churn rate
100GB of recovery points
NGT is installed
Recovery points are application-consistent
After replications begin the administrator quickly notices replications are not progressing.
What best explains what happened?
Question # 13
A company ' s two clusters are part of the same availability zone. Prism Central, which holds the protection policy configuration and recovery plans, is located on Cluster A and protected by the Prism Central Backup and Restore mechanism. What is the first step to take to execute a disaster recovery plan on the datacenter hosting Cluster A?
Question # 14
An administrator is preparing to configure DR between an on-prem AZ and Nutanix Cloud AZ. Replication fails immediately after configuration. Which prerequisite should be verified?
Question # 15
An administrator executes an Unplanned Failover of web server VMs from an on-premises AZ to a Nutanix Cloud Cluster (NC2) on AWS. The Recovery Plan completes, and the VMs are running. However, external users cannot access the websites hosted on these VMs. The administrator verifies that the firewall rules are set correctly. What specific configuration is required for these VMs to be reachable from the external network after failover to NC2?
Question # 16
An administrator recently expanded a Nutanix cluster by adding several new nodes. Shortly after, multiple backup jobs began failing. The following error is consistently reported: " Failed to perform backup: Cannot complete process ' iscsiadm --mode discovery --type sendtargets --portal X.X.X.X ' within timeout " . What is the most likely cause of the failure?
Question # 17
When designing a Disaster Recovery strategy to an NC2 cluster using MST, which technical limitation impacts the Recovery Plan and workload compatibility?
Question # 18
What must an administrator verify before starting a migration of entities from a protection domain to a protection policy?
Question # 20
After an unplanned outage, all VMs were successfully failed over to the recovery site, and users are now accessing workloads from there. The DR dashboard shows the failover is complete and replication from the original primary site has stopped. As part of post-failover cleanup, what is the most appropriate next action to ensure the DR configuration reflects the current production state and is ready for future protection?
Question # 21
An administrator incorrectly used the " Activate " functionality on the PD to test failover of VMs from production to DR cluster. The VMs were successfully restored on the DR side. What steps are needed to clean up the VMs on the DR side and resume normal operations on the Production cluster?
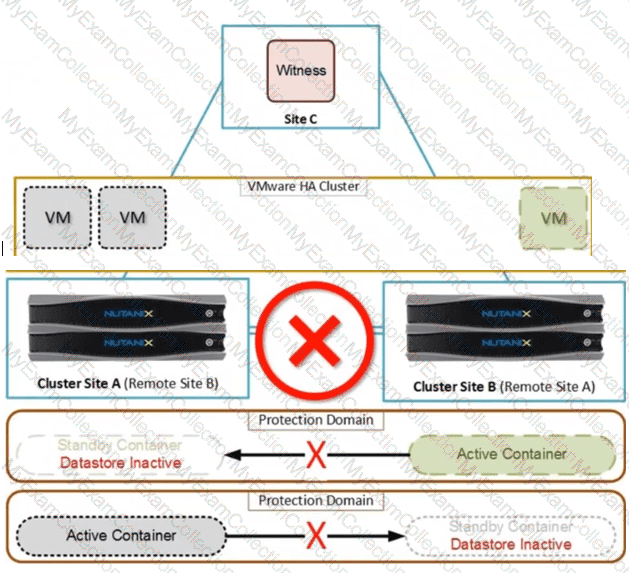
Question # 22
Refer to Exhibit:
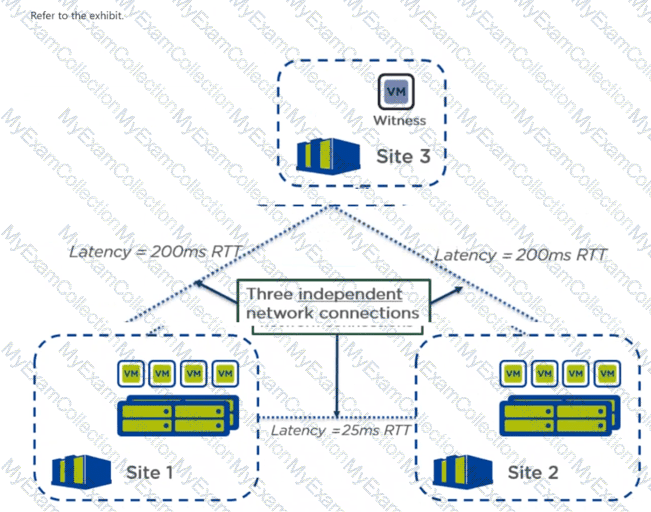
An administrator is configuring Metro Availability in their environment, as shown in the diagram. What issue in the configuration will prevent Metro from working correctly?
Question # 23
An administrator is tasked with ensuring the VMs do not experience downtime during an upcoming network maintenance on the primary cluster. The VMs are protected by a Protection Policy and are configured under a Recovery Plan. What failover mechanism should the administrator use to ensure the VMs are available on the target cluster before the maintenance window?
Question # 24
What snapshot recovery point interval does Self-Service Restore support in a Nearsync setup?
Question # 25
Which ports must remain open to support replication between two Prism Element clusters?
Question # 26
An administrator is managing a mission-critical Inventory-VM that is part of a Protection Domain (PD) named PD_Production.
Monday: A scheduled snapshot of PD_Production is successfully taken.
Tuesday: Due to a configuration error during a cleanup task, the administrator accidentally removes Inventory-VM from the PD_Production Protection Domain. The VM continues to run, but it is no longer being snapped or replicated.
Wednesday: A database corruption occurs on Inventory-VM. The administrator finds the local snapshot from Monday and performs an In-place Restore (Revert) to recover the data.
Following the successful completion of the In-place Restore, what is the status of Inventory-VM regarding its data protection?
Question # 27
An administrator at a retail company is preparing to apply a critical OS security patch to a production SQL Server VM. Before starting, the administrator ensures the VM is part of a Protection Domain and manually creates a local snapshot (Recovery Point). Ten minutes after the patch is applied, the SQL service fails to start, and the database logs indicate corruption in the system registry. The administrator needs to return the VM to its functional state from ten minutes ago as quickly as possible. The administrator decides to perform a Restore from the local snapshot. Under which condition would an In-place Restore (Revert) fail, forcing the administrator to use the Clone (Out-of-place) option instead?
Question # 28
An administrator notices that VM replication from ClusterA to ClusterB fails consistently at the same point during the replication job. The following observations are noted by the administrator:
The Prism dashboard shows the replication job failing during snapshot creation.
ClusterB storage pool and container usage is under 80%, well below capacity.
Network latency/Pings between ClusterA and ClusterB averages 3ms, with occasional spikes to 25ms.
VM event logs indicate frequent I/O timeout errors during the replication window.
Both clusters are running compatible AOS versions.
What is the most likely cause for the failing replications?
Question # 29
Which log file should an administrator review to ensure consistent connectivity stability between primary and remote disaster recovery sites?
Question # 30
A remote office deployment consists of a two-node Nutanix hybrid cluster. An administrator attempts to configure a protection domain with a 5-minute RPO (Nearsync) replicating to a central datacenter.
Why is the administrator unable to successfully configure this Nearsync schedule?
Question # 31
An administrator is tasked with verifying the cluster ' s disaster recovery capability. The administrator needs to validate the capability without impacting the production VMs on the Source cluster and ensure that the destination cluster can bring up all the protected VMs. How can the administrator perform a failover?
Question # 32
A Protection Domain exists with a VM, but no new snapshots are being created and replication never starts. Which is the most likely DR setup issue?

