Question # 4
You have an Azure Databricks workspace that is enabled for Unity Catalog.
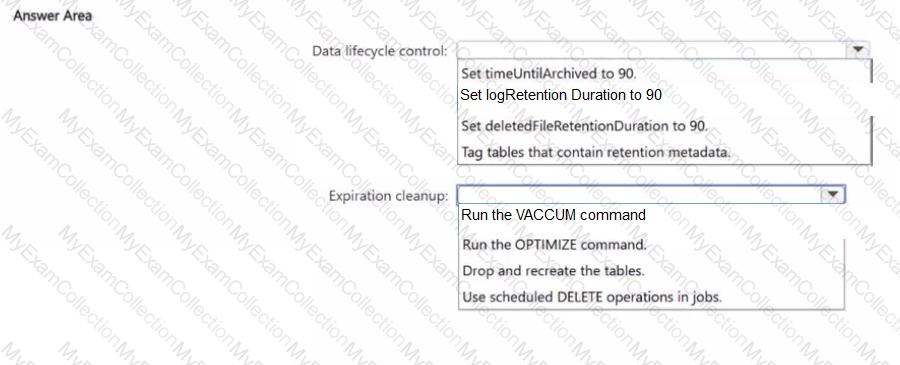
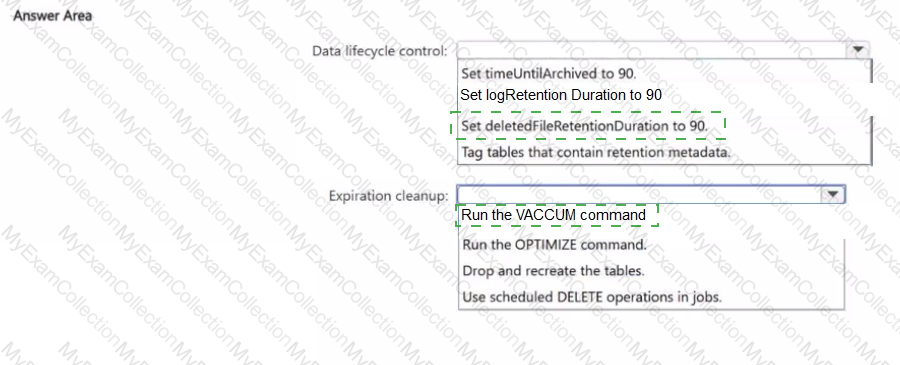
You need to implement a data lifecycle and expiration solution that meets the following requirements
• Transaction logs and deleted data files that are older than 90 days must be removed from Delta tables to reclaim storage.
• All the tables must remain available for querying during the cleanup process.
• Administrative effort must be minimized
What should you do for each requirement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Question # 5
You have an Azure Databricks workspace.
You have an Azure key vault named kv-secure that stores a secret named storageKey. The value of storageKey is managed and updated by the cloud security team at your company.
You need to enable a Databricks notebook named Notebook 1 to retrieve the value of storageKey securely at runtime. The solution must follow the principle of least privilege and always retrieve the latest value.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


Question # 6
You have an Azure Databricks workspace.
You need to ingest streaming data from Azure Event Hubs by using Apache Spark Structured Streaming The solution must authenticate to Event Hubs and read the event payload.
How should you complete the PySpark code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


Question # 7
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a catalog named finance, finance contains two schemas named default and procurement.
You need to create a table named assets in the procurement schema, assets must contain the following columns:
• asset.id
• asset, type
• asset_name
How should you complete the SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.


Question # 8
You have an Azure Databricks workspace that is enabled for Unity Catalog. You plan to run the following PySpark code.

For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


Question # 9
You have an Azure Databricks workspace that contains a job in Lakeflow Jobs named Job1.
Job! processes raw data files stored in Azure Storage.
New files arrive at unpredictable intervals.
You need to ensure that Job1 starts automatically when new files arrive and does NOT consume compute resources when no data is available.
Which type of job trigger should you use?
Question # 10
You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
Question # 11
You need to develop the task logic for a new job in Lakeflow Jobs that processes telemetry data.
Each task must contain only the appropriate logic for its step in the pipeline. The solution must support the planned changes and meet the data ingestion and processing requirements.
What should you do?
Question # 12
Which SCD type should you use to support the planned data modeling changes? To answer, drag the appropriate types to the correct issues. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


Question # 13
You need to complete the PySpark code for the Spark Structured Streaming pipelines. The solution must meet the data ingestion and processing requirements.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


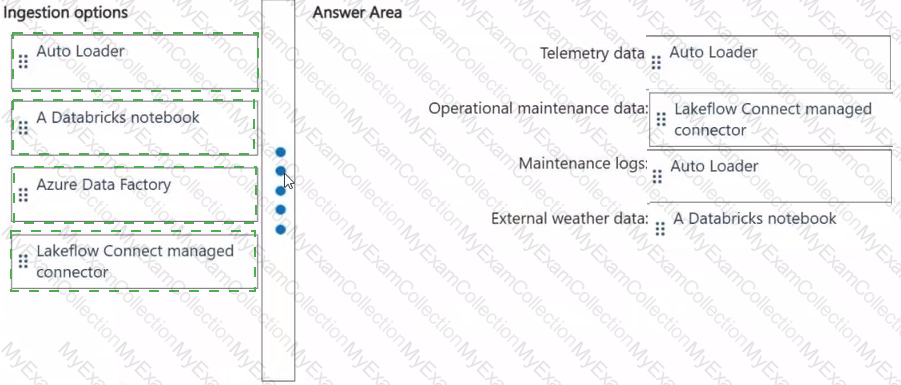
Question # 14
Which ingestion option should you recommend for each data source? To answer, drag the appropriate options to the correct data sources. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.