Choosing Examcollection DP-700 VCE to Ensure Career Goals
MyExamCollection offers a premier pathway to success in the DP-700 exam, a crucial certification in the IT industry. By utilizing Examcollection DP-700 PDF, candidates can align their preparation with their professional ambitions, ensuring they reach their goals with confidence.
Unique DP-700 Exam Dumps Questions for MyExamCollection
One of the standout features of MyExamCollection’s DP-700 PDF is its unique dumps questions And answers. These questions are crafted by MyExamCollection experts, drawing from a wealth of experience and knowledge. Each question is designed to reflect the format and difficulty level of the actual exam, ensuring candidates are well-prepared for what they will encounter on test day.
The DP-700 practice questions cover the entire syllabus and are frequently updated to reflect any changes in exam standards. This tailored approach not only enhances understanding of key concepts but also boosts retention and recall, providing a comprehensive study experience. With MyExamCollection, candidates can familiarize themselves with the types of questions they may face, thus reducing anxiety and improving overall performance.
One-Stop Solution for Passing the Microsoft DP-700 Practice Test Questions
MyExamCollection serves as a one-stop solution for all DP-700 exam preparation needs. From study guides and detailed explanations to practice tests and braindumps, the resources provided are designed to streamline the learning process.
MyExamCollection offers a structured learning path that allows candidates to progress at their own pace. With DP-700 practice tests simulating real exam conditions, users can effectively gauge their understanding and readiness. The inclusion of explanatory notes further clarifies complex topics, making it easier for learners to grasp difficult concepts.
Additionally, the content is organized in a user-friendly manner, allowing candidates to easily navigate through the Study materials. Whether you are a beginner or looking to refresh your knowledge, MyExamCollection equips you with all the tools necessary to succeed.
Money-Back Guarantee Success
To instill confidence in their products, MyExamCollection offers a money-back guarantee. This commitment to customer satisfaction means that if candidates do not achieve their desired results, they can request a refund. This policy demonstrates MyExamCollection’s confidence in the effectiveness of their Dumps materials and serves as a safety net for those investing in their professional growth.
Choosing Examcollection Microsoft DP-700 Dumps is an excellent decision for anyone looking to advance their IT career. With Real Practice test questions And Answers, a comprehensive one-stop solution for DP-700 exam preparation, and a money-back guarantee, MyExamCollection stands out as a reliable partner in achieving Microsoft Certified: Fabric Data Engineer Associate certification success. Equip yourself with the best resources, and take the next step towards realizing your professional aspirations.
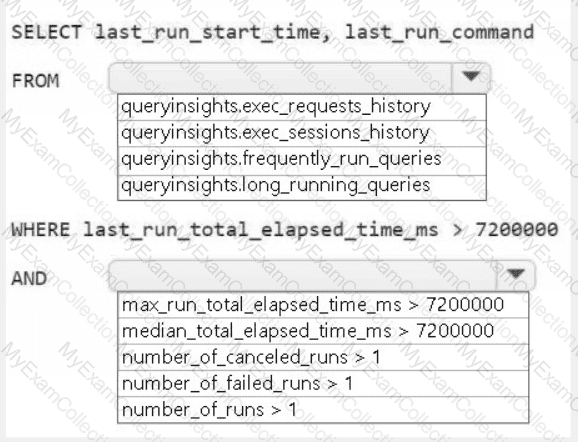
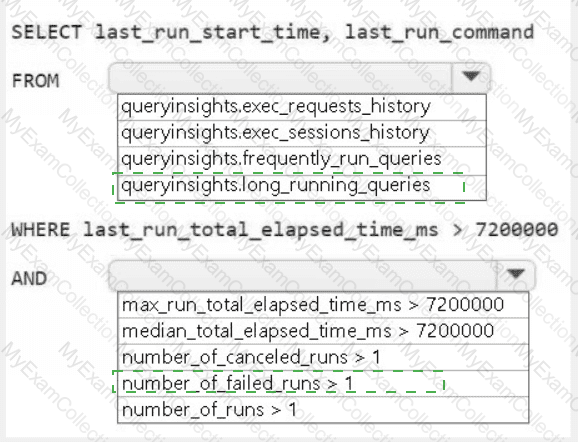
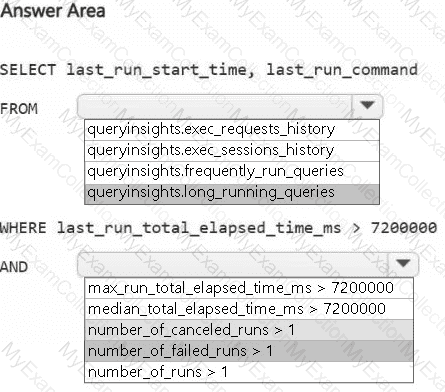 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generated
