Question # 4
A data scientist has created a Python functioncompute_featuresthat returns a Spark DataFrame with the following schema:

The resulting DataFrame is assigned to thefeatures_dfvariable. The data scientist wants to create a Feature Store table usingfeatures_df.
Which of the following code blocks can they use to create and populate the Feature Store table using the Feature Store Clientfs?
A.

B.

C.
features_df.write.mode("fs").path("new_table")
D.

E.
features_df.write.mode("feature").path("new_table")
Question # 5
A machine learning engineering team has written predictions computed in a batch job to a Delta table for querying. However, the team has noticed that the querying is running slowly. The team has alreadytuned the size of the data files. Upon investigating, the team has concluded that the rows meeting the query condition are sparsely located throughout each of the data files.
Based on the scenario, which of the following optimization techniques could speed up the query by colocating similar records while considering values in multiple columns?
Question # 6
In a continuous integration, continuous deployment (CI/CD) process for machine learning pipelines, which of the following events commonly triggers the execution of automated testing?
Question # 7
A machine learning engineer is attempting to create a webhook that will trigger a Databricks Jobjob_idwhen a model version for modelmodeltransitions into any MLflow Model Registry stage.
They have the following incomplete code block:

Which of the following lines of code can be used to fill in the blank so that the code block accomplishes the task?
Question # 8
Which of the following deployment paradigms can centrally compute predictions for a single record with exceedingly fast results?
Question # 9
After a data scientist noticed that a column was missing from a production feature set stored as a Delta table, the machine learning engineering team has been tasked with determining when the column was dropped from the feature set.
Which of the following SQL commands can be used to accomplish this task?
Question # 10
Which of the following is a simple, low-cost method of monitoring numeric feature drift?
Question # 11
A data scientist wants to remove the star_rating column from the Delta table at the location path. To do this, they need to load in data and drop the star_rating column.
Which of the following code blocks accomplishes this task?
Question # 12
A machine learning engineer wants to log feature importance data from a CSV file at path importance_path with an MLflow run for model model.
Which of the following code blocks will accomplish this task inside of an existing MLflow run block?
A.

B.

C.
mlflow.log_data(importance_path, "feature-importance.csv")
D.
mlflow.log_artifact(importance_path, "feature-importance.csv")
E.
None of these code blocks tan accomplish the task.
Question # 13
A data scientist is using MLflow to track their machine learning experiment. As a part of each MLflow run, they are performing hyperparameter tuning. The data scientist would like to have one parent run for the tuning process with a child run for each unique combination of hyperparameter values.
They are using the following code block:

The code block is not nesting the runs in MLflow as they expected.
Which of the following changes does the data scientist need to make to the above code block so that it successfully nests the child runs under the parent run in MLflow?
Question # 14
A data scientist has computed updated feature values for all primary key values stored in the Feature Store table features. In addition, feature values for some new primary key values have also been computed. The updated feature values are stored in the DataFrame features_df. They want to replace all data in features with the newly computed data.
Which of the following code blocks can they use to perform this task using the Feature Store Client fs?
A)

B)

C)

D)
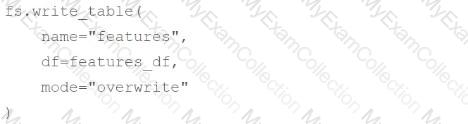
E)

Question # 15
A machine learning engineer is in the process of implementing a concept drift monitoring solution. They are planning to use the following steps:
1. Deploy a model to production and compute predicted values
2. Obtain the observed (actual) label values
3. _____
4. Run a statistical test to determine if there are changes over time
Which of the following should be completed as Step #3?
Question # 16
A machine learning engineer has deployed a model recommender using MLflow Model Serving. They now want to query the version of that model that is in the Production stage of the MLflow Model Registry.
Which of the following model URIs can be used to query the described model version?
Question # 17
Which of the following tools can assist in real-time deployments by packaging software with its own application, tools, and libraries?
Question # 18
A machine learning engineer wants to programmatically create a new Databricks Job whose schedule depends on the result of some automated tests in a machine learning pipeline.
Which of the following Databricks tools can be used to programmatically create the Job?

