Question # 4
A data analyst is using Databricks Unity Catalog. The datasets are tagged by sensitivity, and confidential data is marked with the tag key confidential. The data analyst needs to quickly find all tables tagged as confidential to review their access permissions in the Databricks workspace search bar.
Which search key text should the data analyst use to find these tables?
Question # 5
A database was created in Databricks SQL using the following statement:
CREATE SCHEMA accounting LOCATION ' dbfs:/accounting/data ' ;
Where will data for this database be stored?
Question # 6
Query History provides Databricks SQL users with a lot of benefits. A data analyst has been asked to share all of these benefits with their team as part of a training exercise. One of the benefit statements the analyst provided to their team is incorrect.
Which statement about Query History is incorrect?
Question # 7
Which of the following SQL keywords can be used to convert a table from a long format to a wide format?
Question # 8
Which of the following approaches can be used to connect Databricks to Fivetran for data ingestion?
Question # 9
Which of the following is a benefit of Databricks SQL using ANSI SQL as its standard SQL dialect?
Question # 10
A managed table and an unmanaged external table were both created in Databricks SQL, and data was ingested into each table. Later, both tables were dropped.
What is the status of data for each of those tables?
Question # 11
A data analysis team is working with the table_bronze SQL table as a source for one of its most complex projects. A stakeholder of the project notices that some of the downstream data is duplicative. The analysis team identifies table_bronze as the source of the duplication.
Which of the following queries can be used to deduplicate the data from table_bronze and write it to a new table table_silver?
A)
CREATE TABLE table_silver AS
SELECT DISTINCT *
FROM table_bronze;
B)
CREATE TABLE table_silver AS
INSERT *
FROM table_bronze;
C)
CREATE TABLE table_silver AS
MERGE DEDUPLICATE *
FROM table_bronze;
D)
INSERT INTO TABLE table_silver
SELECT * FROM table_bronze;
E)
INSERT OVERWRITE TABLE table_silver
SELECT * FROM table_bronze;
Question # 12
How can a data analyst determine if query results were pulled from the cache?
Question # 13
A data analyst needs to create an empty managed table table_name in database database_name with a specific schema. The table needs to be recreated and empty, regardless of whether or not the table already exists.
Which command can the analyst use to complete the task?
Question # 14
A data analyst at an e-commerce company needs to process daily sales data. The data consists of approximately 50,000 records stored in a single CSV file, totaling about 20 MB. The analyst needs to perform aggregations and generate a summary report.
Which approach could the data analyst use in this situation?
Question # 15
An analyst writes a query that contains a query parameter. They then add an area chart visualization to the query. While adding the area chart visualization to a dashboard, the analyst chooses " Dashboard Parameter " for the query parameter associated with the area chart.
Which of the following statements is true?
Question # 16
A data analyst filters rows where the tags array includes the value ' sql ' using this query:
SELECT *
FROM main.analytics.articles
WHERE tags = ' sql ' ;
This query returns no results.
How should the analyst query to filter for rows where the tags array contains ' sql ' ?
Question # 17
Consider the following two statements:
Statement 1:

Statement 2:
Which of the following describes how the result sets will differ for each statement when they are run in Databricks SQL?
Question # 18
A data analyst is processing a complex aggregation on a table with zero null values and their query returns the following result:
Which of the following queries did the analyst run to obtain the above result?
A)
B)
C)
D)
E)

Question # 19
A data analyst is working on a DataFrame named dates_df and needs to add a new column, date, derived from the timestamp field.
Which code fragment should be used to extract the date from a timestamp?
Question # 20
A Data Analyst is working on sensor_df; this DataFrame contains two columns: record_datetime timestamp and record array.
Which code fragment returns a DataFrame that splits the record column into separate columns and has one array item per row?
Question # 21
A data analysis team has noticed that their Databricks SQL queries are running too slowly when connected to their always-on SQL endpoint. They claim that this issue is present when many members of the team are running small queries simultaneously. They ask the data engineering team for help. The data engineering team notices that each of the team’s queries uses the same SQL endpoint.
Which of the following approaches can the data engineering team use to improve the latency of the team’s queries?
Question # 22
Data professionals with varying titles use the Databricks SQL service as the primary touchpoint with the Databricks Lakehouse Platform. However, some users will use other services like Databricks Machine Learning or Databricks Data Science and Engineering.
Which of the following roles uses Databricks SQL as a secondary service while primarily using one of the other services?
Question # 23
A data engineering team has created a Structured Streaming pipeline that processes data in micro-batches and populates gold-level tables. The microbatches are triggered every minute.
A data analyst has created a dashboard based on this gold-level data. The project stakeholders want to see the results in the dashboard updated within one minute or less of new data becoming available within the gold-level tables.
Which of the following cautions should the data analyst share prior to setting up the dashboard to complete this task?
Question # 24
A data analyst has created a Query in Databricks SQL, and now wants to create two data visualizations from that Query and add both of those data visualizations to the same Databricks SQL Dashboard.
Which step will the data analyst need to take when creating and adding both data visualizations to the Databricks SQL Dashboard?
Question # 25
A business analyst has been asked to create a data entity/object called sales_by_employee. It should always stay up-to-date when new data are added to the sales table. The new entity should have the columns sales_person, which will be the name of the employee from the employees table, and sales, which will be all sales for that particular sales person. Both the sales table and the employees table have an employee_id column that is used to identify the sales person.
Which of the following code blocks will accomplish this task?
A)

B)

C)
D)

Question # 27
What is an advantage of using a Delta Lake-based data lakehouse over classic enterprise data warehouse solutions?
Question # 28
A data analyst is processing a complex aggregation on a table with zero null values and the query returns the following result:
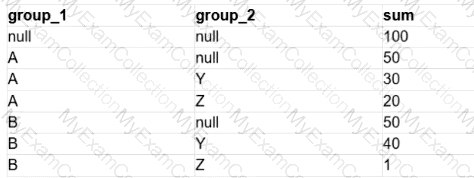
Which query did the analyst execute in order to get this result?
A)

B)

C)

D)

Question # 29
Data engineers and data analysts are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL. The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which of the following changes will need to be made to the pipeline when migrating to Delta Live Tables?
Question # 31
Which example of data projects represents a common analytics application to be completed in Databricks SQL?
Question # 32
An analyst has been asked to combine the data in two tables: suppliers and new_suppliers. It is possible that some of the supplier_id values match in both tables, meaning those suppliers have already been added to the suppliers table. If that is the case, the data should be unchanged.
Which command will combine the two tables without duplicating the rows with the same supplier_id?
Question # 33
Which of the following layers of the medallion architecture is most commonly used by data analysts?
Question # 34
Which of the following is stored in the Databricks customer’s cloud account?
Question # 35
A data analyst has produced a visualization. A stakeholder has viewed the visualization and is complaining that the visualization is difficult to interpret. After looking at the visualization, the analyst determines that the scale of the y-axis must be changed.
Where are the controls for changing the scale of the y-axis in Databricks SQL?

