Question # 4
A healthcare company experiences a cyberattack, where the hackers were able to reverse-engineer a dataset to break confidentiality.
Which of the following is TRUE regarding the dataset parameters?
Question # 5
Which of the following models are text vectorization methods? (Select two.)
Question # 6
In which of the following scenarios is lasso regression preferable over ridge regression?
Question # 7
Which of the following tests should be performed at the production level before deploying a newly retrained model?
Question # 8
A change in the relationship between the target variable and input features is
Question # 9
Which three security measures could be applied in different ML workflow stages to defend them against malicious activities? (Select three.)
Question # 10
Which of the following is the primary purpose of hyperparameter optimization?
Question # 12
You and your team need to process large datasets of images as fast as possible for a machine learning task. The project will also use a modular framework with extensible code and an active developer community. Which of the following would BEST meet your needs?
Question # 13
The following confusion matrix is produced when a classifier is used to predict labels on a test dataset. How precise is the classifier?
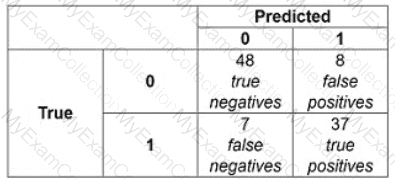
Question # 14
Which of the following principles supports building an ML system with a Privacy by Design methodology?
Question # 15
Which of the following describes a neural network without an activation function?
Question # 16
Which of the following is a type 1 error in statistical hypothesis testing?
Question # 17
You have a dataset with thousands of features, all of which are categorical. Using these features as predictors, you are tasked with creating a prediction model to accurately predict the value of a continuous dependent variable. Which of the following would be appropriate algorithms to use? (Select two.)
Question # 18
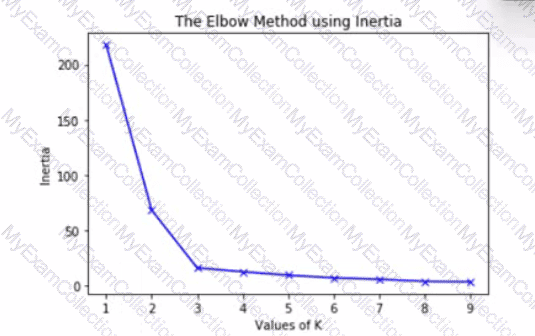
The graph is an elbow plot showing the inertia or within-cluster sum of squares on the y-axis and number of clusters (also called K) on the x-axis, denoting the change in inertia as the clusters change using k-means algorithm.
What would be an optimal value of K to ensure a good number of clusters?
Question # 19
Which two of the following decrease technical debt in ML systems? (Select two.)
Question # 20
Which of the following occurs when a data segment is collected in such a way that some members of the intended statistical population are less likely to be included than others?
Question # 22
You are implementing a support-vector machine on your data, and a colleague suggests you use a polynomial kernel. In what situation might this help improve the prediction of your model?
Question # 25
Which two of the following criteria are essential for machine learning models to achieve before deployment? (Select two.)
Question # 26
Which of the following items should be included in a handover to the end user to enable them to use and run a trained model on their own system? (Select three.)
Question # 27
Word Embedding describes a task in natural language processing (NLP) where:

