Question # 4
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

The question describes a process where an AI system generates text that describes an image — for example, “A dog playing with a ball in the park.†This process is an example of image classification, a core workload in computer vision that allows a system to recognize and categorize the content of an image.
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify Azure services for computer vision,†image classification involves analyzing the pixels of an image and assigning one or more predefined categories or labels to it. In more advanced implementations, image classification models are combined with caption generation algorithms to produce descriptive text. For example, Azure AI Vision can generate captions and tags that describe an image’s content, such as “outdoor scene,†“a person riding a bicycle,†or “a group of people smiling.â€
Let’s review the other options to clarify why they are incorrect:
Facial detection: Identifies the presence and location of human faces in an image, but does not generate descriptive text.
Object detection: Identifies and locates multiple objects within an image by drawing bounding boxes, not by describing the overall scene.
Optical character recognition (OCR): Extracts text from images or scanned documents (for example, reading a street sign), but it doesn’t create descriptive language about what’s depicted.
Therefore, the correct answer is Image classification, as it aligns with the AI-900 learning objective that describes this task as recognizing and categorizing the main content of an image, often leading to caption generation in modern vision models such as those in Azure AI Vision.
Question # 5
Which two scenarios are examples of a conversational AI workload? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A.
a telephone answering service that has a pre-recorder message
B.
a chatbot that provides users with the ability to find answers on a website by themselves
C.
telephone voice menus to reduce the load on human resources
D.
a service that creates frequently asked questions (FAQ) documents by crawling public websites
Full Access
Answer:
B, C
Explanation:
According to the AI-900 official study guide and Microsoft Learn module “Describe features of conversational AI workloads on Azureâ€, conversational AI refers to artificial intelligence systems that interact with users through natural language via text or speech. These systems include chatbots, virtual assistants, and interactive voice response (IVR) systems that simulate human conversation.
B. Chatbot that provides users with the ability to find answers on a website by themselvesThis is a classic example of conversational AI. Chatbots use natural language understanding (LUIS) and Azure Bot Service to interpret user input, identify intent, and provide relevant responses automatically. They help users self-serve information without human support, such as retrieving account details or answering FAQs.
C. Telephone voice menus to reduce the load on human resourcesAutomated telephone systems or IVRs use conversational AI to interpret spoken commands and route calls intelligently. This is often implemented using Azure Cognitive Services Speech (for speech-to-text and text-to-speech) combined with Azure Bot Service for managing dialogue flow.
Question # 6
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

In Azure OpenAI Service, the temperature parameter directly controls the creativity and determinism of responses generated by models such as GPT-3.5. According to the Microsoft Learn documentation for Azure OpenAI models, temperature is a numeric value (typically between 0.0 and 2.0) that determines how “random†or “deterministic†the output should be.
A lower temperature value (for example, 0 or 0.2) makes the model’s responses more deterministic, meaning the same prompt consistently produces nearly identical outputs.
A higher temperature value (for example, 0.8 or 1.0) encourages creativity and variety, causing the model to generate different phrasing or interpretations each time it responds.
When a question specifies the need for more deterministic responses, Microsoft’s guidance is to decrease the temperature parameter. This adjustment makes the model focus on the most probable tokens (words) rather than exploring less likely options, improving reliability and consistency—ideal for business or technical applications where consistent answers are essential.
The other parameters serve different purposes:
Frequency penalty reduces repetition of the same phrases but does not control randomness.
Max response (max tokens) limits the maximum length of the generated output.
Stop sequence defines specific tokens that tell the model when to stop generating text.
Thus, the correct and Microsoft-verified completion is:
“You can modify the Temperature parameter to produce more deterministic responses from a chat solution that uses the Azure OpenAI GPT-3.5 model.â€
Question # 7
You need to generate cartoons for use in a brochure. Each cartoon will be based on a text description.
Which Azure OpenAI model should you use?
A.
Codex
B.
DALL-E
C.
GPT-3.5
D.
GPT-4
Full Access
Answer:
B
Explanation:
To generate cartoons or images from text descriptions, the correct Azure OpenAI model is DALL-E. As described in Microsoft’s OpenAI integration documentation, DALL-E is a generative image model that converts natural language prompts into images, illustrations, and artwork.
Codex is for code generation, GPT-3.5 and GPT-4 are for text and reasoning tasks, not image creation. Therefore, B. DALL-E is correct.
Question # 8
To complete the sentence, select the appropriate option in the answer area.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) study guide and official Microsoft Learn modules under “Describe features of common AI workloadsâ€, Conversational AI refers to technology that enables computers to engage in dialogue or conversation with users through natural language, whether by text or speech. The interactive answering of user-entered questions through a chat interface or virtual assistant is a direct example of a conversational AI workload.
Microsoft defines Conversational AI as systems that use natural language processing (NLP) and language understanding models to interpret what users are asking and respond appropriately. This includes chatbots, virtual assistants (like Cortana or Azure Bot Service), and automated customer service systems that simulate a human-like conversation. In this case, when an application answers questions that a user types interactively, the AI model is processing human language inputs, deriving intent, and generating meaningful replies — precisely what conversational AI is designed to do.
By contrast:
Anomaly detection identifies unusual patterns in data, typically used for fraud detection or equipment monitoring — not interactive dialogue.
Computer vision deals with interpreting images or video (e.g., object detection, facial recognition), unrelated to answering text-based questions.
Forecasting uses historical data to predict future trends or outcomes, often in sales or demand prediction scenarios.
The AI-900 guide emphasizes that Conversational AI helps businesses improve customer interaction efficiency by offering instant, automated, and consistent responses. It enables real-time engagement 24/7 and integrates with tools such as Azure Bot Service, Azure Cognitive Service for Language, and QnA Maker (now part of Azure AI Language Service).
Therefore, based on the Microsoft Learn objectives and definitions from the official AI-900 curriculum, the interactive answering of user questions in an application is best categorized as Conversational AI.
Question # 9
Which two actions can you perform by using the Azure OpenAI DALL-E model? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
A.
Create images.
B.
Use optical character recognition (OCR).
C.
Detect objects in images.
D.
Modify images.
E.
Generate captions for images.
Full Access
Answer:
A, D
Explanation:
The correct answers are A. Create images and D. Modify images.
The Azure OpenAI DALL-E model is a text-to-image generative AI model that can create original images and modify existing ones based on text prompts. According to Microsoft Learn and Azure OpenAI documentation, DALL-E interprets natural language descriptions to produce unique and creative visual content, making it useful for design, illustration, marketing, and educational applications.
Create images (A) – DALL-E can generate new images entirely from textual input. For example, the prompt “a futuristic city skyline at sunrise†would result in a custom-generated artwork that visually represents that description.
Modify images (D) – DALL-E also supports inpainting and outpainting, allowing users to edit or expand existing images. You can replace parts of an image (for example, changing a background or object) or add new elements consistent with the visual style of the original.
The remaining options are incorrect:
B. OCR is performed by Azure AI Vision, not DALL-E.
C. Detect objects in images is also an Azure AI Vision (Image Analysis) feature.
E. Generate captions for images is handled by Azure AI Vision, not DALL-E, since DALL-E generates—not interprets—visuals.
Question # 10
To complete the sentence, select the appropriate option in the answer area.

Full Access
Answer:
Answer: 
Explanation:
Classification
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Describe features of common AI workloadsâ€, classification is a supervised machine learning technique used when the goal is to predict which category or class an item belongs to. In supervised learning, the model is trained with labeled data—data that already contains known outcomes. The system learns patterns and relationships between input features and their corresponding labels so it can predict future classifications accurately.
In the scenario provided — “A banking system that predicts whether a loan will be repaid†— the model’s output is a binary decision, meaning there are two possible outcomes:
The loan will be repaid (positive class)
The loan will not be repaid (negative class)
This kind of problem involves predicting a discrete value (a label or category), not a continuous numeric output. Therefore, it perfectly fits the classification type of machine learning.
The AI-900 learning materials describe classification as being used in many real-world examples, including:
Determining whether an email is spam or not spam.
Predicting whether a customer will churn (leave) or stay.
Detecting fraudulent transactions.
Assessing medical test results as positive or negative.
By contrast:
Regression predicts continuous numeric values, such as predicting house prices, temperatures, or sales revenue. It would not apply here because repayment prediction is not a numeric value but a categorical decision.
Clustering is an unsupervised learning method that groups similar data points without predefined categories, such as segmenting customers by purchasing behavior.
Thus, based on Microsoft’s Responsible AI and AI-900 study guide concepts, a banking system that predicts whether a loan will be repaid uses the Classification type of machine learning.
Question # 11
You need to identify groups of rows with similar numeric values in a dataset. Which type of machine learning should you use?
A.
clustering
B.
regression
C.
classification
Full Access
Answer:
A
Explanation:
When you need to identify groups of rows with similar numeric values in a dataset, the correct machine learning approach is clustering. This method belongs to unsupervised learning, where the model groups data points based on similarity without using pre-labeled training data.
In Azure AI-900 study modules, clustering is introduced as a technique for discovering natural groupings in data. For instance, clustering could be used to group customers with similar purchase histories or to find products with similar features. The algorithm—such as K-means or hierarchical clustering—calculates distances between data points and organizes them into clusters based on how close they are numerically or statistically.
The other options are incorrect:
B. Regression predicts continuous numeric values (e.g., predicting sales or prices).
C. Classification assigns data to predefined categories (e.g., spam or not spam).
Question # 12
You are building a Language Understanding model for an e-commerce business.
You need to ensure that the model detects when utterances are outside the intended scope of the model.
What should you do?
A.
Test the model by using new utterances
B.
Add utterances to the None intent
C.
Create a prebuilt task entity
D.
Create a new model
Full Access
Answer:
B
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of conversational AI workloads on Azureâ€, a Language Understanding (LUIS) model is designed to interpret natural language input by identifying intents (the purpose of an utterance) and entities (specific data items in the utterance).
Every LUIS model automatically includes a special intent called “None.†This intent is used to handle utterances that do not fall into any of the model’s defined intents. Adding examples of irrelevant or out-of-scope utterances to the None intent helps the model learn to recognize when a user’s input does not match any existing categories.
For example, if your e-commerce chatbot handles intents such as “TrackOrder†and “CancelOrder,†but a user says “What’s your favorite color?â€, that input should be mapped to the None intent so the bot can respond appropriately, such as “I’m not sure how to answer that.â€
The AI-900 curriculum emphasizes that including diverse None intent examples improves model robustness and prevents false matches, thereby enhancing user experience.
Other options are incorrect:
A. Test the model by using new utterances: Testing is important but does not define how to detect out-of-scope inputs.
C. Create a prebuilt task entity: Entities extract specific data but are unrelated to intent classification.
D. Create a new model: Unnecessary; handling out-of-scope utterances is done within the same model via the None intent.
✅ Final Answer: B. Add utterances to the None intent
Question # 13
What is a form of unsupervised machine learning?
A.
multiclass classification
B.
clustering
C.
binary classification
D.
regression
Full Access
Answer:
B
Explanation:
As outlined in the AI-900 study guide and Microsoft Learn’s “Explore fundamental principles of machine learning†module, clustering is a core example of unsupervised machine learning.
In unsupervised learning, the model is trained on data without labeled outcomes. The goal is to discover patterns or groupings naturally present in the data. Clustering algorithms, such as K-means, DBSCAN, or Hierarchical clustering, analyze similarities among data points and group them into clusters. For example, clustering can group customers by purchasing behavior or segment products by shared characteristics — all without predefined labels.
Supervised learning, by contrast, uses labeled data (input-output pairs) to train a model that predicts outcomes. This includes:
A. Multiclass classification – Predicts more than two categories (e.g., classifying images as dog, cat, or bird).
C. Binary classification – Predicts two categories (e.g., spam vs. not spam).
D. Regression – Predicts continuous numeric values (e.g., price prediction).
Therefore, the only option representing unsupervised learning is clustering, which enables data discovery without predefined labels.
Question # 14
You are developing a conversational AI solution that will communicate with users through multiple channels including email, Microsoft Teams, and webchat.
Which service should you use?
A.
Text Analytics
B.
Azure Bot Service
C.
Translator
D.
Form Recognizer
Full Access
Answer:
B
Explanation:
According to the Microsoft Azure AI Fundamentals official study guide and Microsoft Learn module “Describe features of conversational AI workloads on Azureâ€, Azure Bot Service is the core Azure platform for building, testing, deploying, and managing conversational agents or chatbots. These bots can communicate with users across multiple channels, including email, Microsoft Teams, Slack, Facebook Messenger, and webchat.
Azure Bot Service integrates deeply with the Bot Framework SDK and Azure Cognitive Services such as Language Understanding (LUIS) or Azure AI Language, enabling natural language processing and multi-channel message delivery. The service abstracts away channel management, meaning that developers can build one bot logic that connects seamlessly to several communication platforms.
Option analysis:
A. Text Analytics is a Cognitive Service used for text mining tasks like key phrase extraction, language detection, and sentiment analysis — not for building chatbots.
C. Translator provides language translation but cannot manage conversations or multi-channel delivery.
D. Form Recognizer extracts structured information from documents and forms — unrelated to conversational interaction.
The AI-900 course explicitly defines Azure Bot Service as “a managed platform that enables intelligent, multi-channel conversational experiences between users and bots.†This service allows businesses to unify chat experiences across multiple digital communication channels.
Thus, based on the official Microsoft Learn content and AI-900 syllabus, the best and verified answer is B. Azure Bot Service, as it is the designated Azure solution for deploying a single conversational AI experience accessible from multiple platforms such as email, Teams, and webchat.
Question # 15
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify features of Natural Language Processing (NLP) workloads and services,†the Azure Cognitive Service for Language – Question Answering capability is designed to allow applications to respond to user questions using information from a prebuilt or custom knowledge base. It relies on Natural Language Processing (NLP) to match user queries to the most relevant answers but does not directly execute queries against databases or infer user intent.
“You can use Language Service’s question answering to query an Azure SQL database.†→ NOThe Question Answering feature does not connect directly to or query structured databases such as Azure SQL. Instead, it retrieves answers from unstructured or semi-structured content (FAQs, manuals, documents). Querying SQL databases would require traditional database access, not a cognitive service.
“You should use Language Service’s question answering when you want a knowledge base to provide the same answer to different users who submit similar questions.†→ YESThis statement is correct and aligns exactly with Microsoft’s official documentation. Question Answering enables organizations to create a knowledge base that can automatically answer repeated or similar customer queries using natural language understanding. For instance, two users asking “How do I reset my password?†and “Can you help me change my password?†would receive the same predefined response.
“Language Service’s question answering can determine the intent of a user utterance.†→ NODetermining user intent is handled by Language Understanding (LUIS) or Conversational Language Understanding, not by Question Answering. While both belong to the Language Service, Question Answering focuses on retrieving relevant answers, whereas LUIS focuses on intent detection and entity extraction.
Question # 16
You have an Al solution that provides users with the ability to control smart devices by using verbal commands.
Which two types of natural language processing (NLP) workloads does the solution use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A.
text-to-speech
B.
translation
C.
language modeling
D.
key phrase extraction
E.
speech-to-text
Full Access
Answer:
C, E
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials and the Microsoft Learn module “Describe features of Natural Language Processing (NLP) workloads on Azureâ€, this scenario combines two major capabilities of AI: speech recognition and natural language understanding.
Speech-to-Text (E) – This is the first step in processing verbal commands. The Azure Speech service converts the spoken words of a user into textual data that can be understood and processed by downstream components. This workload is commonly referred to as speech recognition, and it falls under the speech capabilities of Azure Cognitive Services. Without this transcription process, the system could not interpret the user’s voice input.
Language Modeling (C) – After the speech input is converted into text, the next step is to interpret the meaning of the text so the system can take appropriate action. Language modeling, also known as language understanding, is responsible for identifying the user’s intent (for example, “turn on the lights†or “set the thermostat to 72 degreesâ€) and extracting entities (such as device name or temperature value). In Azure, this function is handled by Language Understanding (LUIS) or Conversational Language Understanding (CLU). These models allow smart systems to process commands and map them to defined actions.
Other options are not correct:
A. Text-to-speech converts text output into spoken language, which is not mentioned as a requirement.
B. Translation converts text from one language to another, irrelevant to this scenario.
D. Key phrase extraction identifies important terms in text but doesn’t interpret or execute commands.
Therefore, the solution uses speech-to-text to transcribe verbal commands and language modeling to understand and act upon them — the two key NLP workloads enabling voice-controlled smart devices.
Question # 17
What is the maximum image size that can be processed by using the prebuilt receipt model in Azure Al Document Intelligence?
A.
5 MB
B.
10MB
C.
50 MB
D.
100 MB
Full Access
Answer:
C
Question # 18
Which two scenarios are examples of a natural language processing workload? Each correct answer presents a complete solution.
NOTE; Each correct selection is worth one point.
A.
assembly line machinery that autonomously inserts headlamps into cars
B.
a smart device in the home that responds to questions such as, " What will the weather be like today?
C.
monitoring the temperature of machinery to turn on a fan when the temperature reaches a specific threshold
D.
a website that uses a knowledge base to interactively respond to users ' questions
Full Access
Answer:
B, D
Explanation:
The correct answers are B. a smart device in the home that responds to questions such as, " What will the weather be like today? " and D. a website that uses a knowledge base to interactively respond to users ' questions.
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify features of Natural Language Processing (NLP) workloads on Azureâ€, Natural Language Processing (NLP) is a branch of artificial intelligence that enables computers to understand, interpret, and generate human language in a meaningful way. NLP bridges the gap between human communication and machine understanding, allowing systems to process both spoken and written language.
Option B – A smart device in the home that responds to questions such as “What will the weather be like today?â€This is an example of an NLP workload because the device must process spoken language (speech-to-text), interpret the user’s intent (language understanding), and generate a relevant spoken response (text-to-speech). This workflow involves several Azure Cognitive Services, such as Speech Service for recognizing and synthesizing speech, and Language Understanding (LUIS) for interpreting intent. This aligns with conversational AI and NLP tasks in the AI-900 syllabus.
Option D – A website that uses a knowledge base to interactively respond to users’ questions.This is also an NLP workload because the system interprets text input from users and retrieves appropriate answers from a knowledge base. Microsoft’s QnA Maker (now part of the Azure AI Language service) and Azure Bot Service enable such behavior. The model uses NLP to understand the user’s question, find the most relevant response, and generate an appropriate reply — key characteristics of natural language processing.
Incorrect options:
A (assembly line machinery) represents automation or robotics, not NLP.
C (monitoring temperature to activate a fan) is an example of an IoT (Internet of Things) or rule-based system, not related to language processing.
Question # 19
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

In Azure Machine Learning Designer, the Dataset output visualization feature is specifically used to explore and understand the distribution of values in potential feature columns before model training begins. This capability is critical for data exploration and preprocessing, two essential stages of the machine learning pipeline described in the Microsoft Azure AI Fundamentals (AI-900) and Azure Machine Learning learning paths.
When a dataset is imported into Azure Machine Learning Designer, users can right-click on the dataset output port and select “Visualizeâ€. This launches the dataset visualization pane, which provides detailed statistical summaries for each column, including:
Data type (numeric, categorical, string, Boolean)
Minimum, maximum, mean, and standard deviation values for numeric columns
Frequency counts and distinct values for categorical columns
Missing value counts
This visual inspection helps determine which columns should be used as features, which might need normalization or encoding, and which contain missing or irrelevant data. It is a vital step in ensuring the dataset is clean and ready for model training.
Let’s examine why other options are incorrect:
Normalize Data module is used to scale numeric data, not to visualize distributions.
Select Columns in Dataset module is used to include or exclude columns, not to analyze them.
Evaluation results visualization feature is used after model training to interpret performance metrics like accuracy or recall, not data distributions.
Therefore, based on official Microsoft documentation and AI-900 study materials, to explore the distribution of values in potential feature columns, you use the Dataset output visualization feature in Azure Machine Learning Designer.
Question # 20
Which two scenarios are examples of a conversational AI workload? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A.
a smart device in the home that responds to questions such as “What will the weather be like today?â€
B.
a website that uses a knowledge base to interactively respond to users’ questions
C.
assembly line machinery that autonomously inserts headlamps into cars
D.
monitoring the temperature of machinery to turn on a fan when the temperature reaches a specificThreshold
Full Access
Answer:
A, B
Explanation:
Conversational AI workloads involve human-like dialogue with AI systems.
A: A smart assistant (e.g., smart speaker) uses voice-based conversational AI.
B: A knowledge-based chatbot interacts with users via natural language.Options C and D describe automation/IoT workloads, not conversational AI.
✅ Final Answer (Q110): A and B
Question # 21
brectly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of common AI workloadsâ€, OCR (Optical Character Recognition) is a Computer Vision technology that detects and extracts printed or handwritten text from images and scanned documents. OCR allows organizations and individuals to convert physical or image-based text into machine-readable, editable, and searchable digital text.
In the context of this question, a historian working with old newspaper articles or archival documents would use OCR to digitize printed content. For instance, the historian can scan or photograph old newspaper pages, and then use an OCR tool—such as Azure Computer Vision’s OCR API—to automatically recognize and extract the textual content from those images. This process enables the historian to store, edit, and analyze the content digitally without manually typing everything.
OCR works by using deep learning algorithms trained on thousands of text samples. The system analyzes patterns, shapes, and spatial relationships of characters to identify text accurately, even from low-quality or aged paper documents. Once extracted, the digital text can be indexed, translated, or processed further using Natural Language Processing (NLP) tools for content analysis.
Now, addressing the other options:
Facial analysis is used to detect emotions, age, or gender from human faces—irrelevant to text digitization.
Image classification identifies entire images by categories (e.g., cat, car, flower).
Object detection identifies and locates multiple objects within an image but doesn’t extract text.
Therefore, per the AI-900 learning objectives under the Computer Vision workload, the correct and verified completion is:
Question # 22
Which metric can you use to evaluate a classification model?
A.
true positive rate
B.
mean absolute error (MAE)
C.
coefficient of determination (R2)
D.
root mean squared error (RMSE)
Full Access
Answer:
A
Explanation:
For evaluating a classification model, the appropriate metric from the options provided is the True Positive Rate (TPR), also known as Sensitivity or Recall. According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Evaluate model performanceâ€, classification models are evaluated using metrics that measure how accurately the model predicts categorical outcomes such as “yes/no,†“spam/not spam,†or “approved/denied.â€
The True Positive Rate measures the proportion of correctly identified positive cases out of all actual positive cases. Mathematically, it is expressed as:
True Positive Rate (Recall)=True PositivesTrue Positives + False Negatives\text{True Positive Rate (Recall)} = \frac{\text{True Positives}}{\text{True Positives + False Negatives}}True Positive Rate (Recall)=True Positives + False NegativesTrue Positives​
This metric is important when missing positive predictions carries a high cost, such as in medical diagnosis or fraud detection. Microsoft Learn highlights classification evaluation metrics such as accuracy, precision, recall, F1 score, and AUC (Area Under the Curve) as suitable for classification models.
The other options—Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and Coefficient of Determination (R²)—are regression metrics used to evaluate models that predict numeric values rather than categories. For example, they apply to predicting house prices or temperatures, not yes/no decisions.
Therefore, the correct classification evaluation metric among the choices is A. True Positive Rate.
[Reference:Microsoft Learn – Evaluate model performance – Understand metrics for classification and regression models, , , , , ]
Question # 23
What is an example of a Microsoft responsible Al principle?
A.
Al systems should protect the interests of developers.
B.
Al systems should be in the public domain.
C.
Al systems should be secure and respect privacy.
D.
Al systems should make personal details accessible.
Full Access
Answer:
C
Explanation:
Microsoft’s Responsible AI principles are central to the AI-900 curriculum and consist of six key tenets:
Fairness – AI systems should treat all people fairly.
Reliability and safety – AI systems should perform reliably and safely.
Privacy and security – AI systems should be secure and respect user privacy.
Inclusiveness – AI systems should empower everyone.
Transparency – AI systems should be understandable.
Accountability – People should be accountable for AI outcomes.
The statement “AI systems should be secure and respect privacy†reflects the Privacy and Security principle, which ensures AI solutions protect personal data and operate within compliance frameworks. Microsoft’s responsible AI framework emphasizes building trust by safeguarding sensitive data used in AI applications.
The other options do not align with official responsible AI principles; for example, AI systems need not “be in the public domain,†nor are they meant to prioritize developers’ interests or expose personal details. Hence, the correct and Microsoft-verified answer is C. AI systems should be secure and respect privacy.
Question # 24
You have a large dataset that contains motor vehicle sales data.
You need to train an automated machine learning (automated ML) model to predict vehicle sale values based on the type of vehicle.
Which task should you select? To answer, select the appropriate task in the answer area.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:
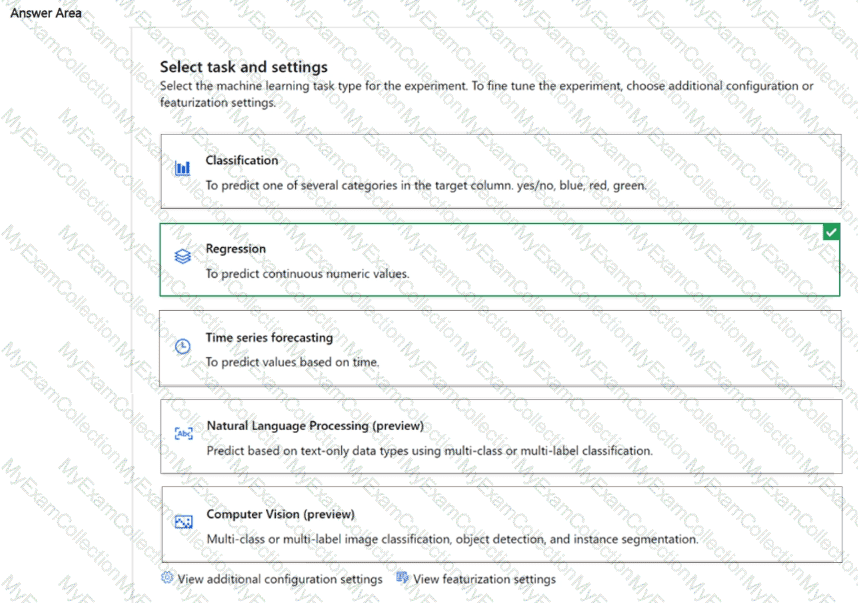
According to the Microsoft Azure AI Fundamentals (AI-900) and Azure Machine Learning documentation, regression is the appropriate machine learning task when the goal is to predict continuous numeric values—such as prices, sales amounts, or other measurable quantities.
In this scenario, the dataset contains motor vehicle sales data, and the objective is to predict vehicle sale values. A vehicle’s sale value (price) is a continuous numeric variable, meaning it can take on a wide range of possible numbers (for example, $15,000, $28,500, $42,300). Regression models are designed to analyze relationships between input features (like make, model, mileage, age, fuel type) and a continuous output variable (price).
Automated Machine Learning (AutoML) in Azure simplifies this process by automatically testing multiple regression algorithms (e.g., Linear Regression, Random Forest, Gradient Boosted Trees) and hyperparameters to find the best-performing model.
Let’s evaluate why the other options are incorrect:
Classification – Used for predicting discrete categories (e.g., car type: sedan, SUV, or truck). Sale value prediction is not categorical.
Time series forecasting – Used when predicting future values based on time-dependent data (e.g., sales over months or years). The question focuses on predicting price based on vehicle characteristics, not over time.
Natural Language Processing (NLP) – Deals with text-based data, not numeric vehicle data.
Computer Vision – Applies to image-based tasks (e.g., detecting car types from photos).
Therefore, per Microsoft Learn’s Automated ML task selection guidance, when predicting a numeric output like vehicle sale value, the correct machine learning task type is Regression.
✅ Final Answer: Regression
Question # 25
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:
Yes, Yes, and No.
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials and the Microsoft Learn module “Identify features of natural language processing (NLP) workloads on Azureâ€, the Azure Translator service is a cloud-based AI service within Azure Cognitive Services that provides real-time text translation across multiple languages.
“You can use the Translator service to translate text between languages.†– Yes.This is the core function of the Translator service. It takes text as input in one language and returns it in another using advanced neural machine translation models. This aligns with the AI-900 learning objective: “Describe the capabilities of Azure Cognitive Services for languageâ€, which specifically names Azure Translator as the service used to perform automatic text translation. The service supports over 100 languages and dialects, offering both single-sentence and document-level translations.
“You can use the Translator service to detect the language of a given text.†– Yes.This statement is also true. The Translator service automatically detects the source language if it is not specified in the request. This feature is documented in the Azure Translator API, where the system identifies the input language before performing translation. The AI-900 exam content emphasizes this as one of the Translator service’s built-in capabilities—language detection for untagged text.
“You can use the Translator service to transcribe audible speech into text.†– No.This is not a function of Translator. Transcription (converting speech to text) is a speech AI workload, handled by the Azure Speech Service, not Translator. The Speech-to-Text capability in Azure Cognitive Services processes spoken audio input and returns the text transcription. The Translator service only works with text input, not direct audio.
Therefore, based on official AI-900 guidance, the verified configuration is:
✅ Yes – for text translation
✅ Yes – for language detection
⌠No – for speech transcription.
This aligns precisely with the AI-900 learning outcomes describing Text Translation and Language Detection as Translator capabilities, and Speech Transcription as part of the separate Speech service.
Question # 26
What are two metrics that you can use to evaluate a regression model? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A.
coefficient of determination (R2)
B.
F1 score
C.
root mean squared error (RMSE)
D.
area under curve (AUC)
E.
balanced accuracy
Full Access
Answer:
A, C
Explanation:
A: R-squared (R2), or Coefficient of determination represents the predictive power of the model as a value between -inf and 1.00. 1.00 means there is a perfect fit, and the fit can be arbitrarily poor so the scores can be negative.
C: RMS-loss or Root Mean Squared Error (RMSE) (also called Root Mean Square Deviation, RMSD), measures the difference between values predicted by a model and the values observed from the environment that is being modeled.
[Reference:, https://docs.microsoft.com/en-us/dotnet/machine-learning/resources/metrics, , , , , ]
Question # 27
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Describe features of natural language processing (NLP) workloads on Azure,†Natural Language Processing refers to the branch of AI that enables computers to interpret, understand, and generate human language. One of the main NLP workloads identified by Microsoft is speech-to-text conversion, which transforms spoken words into written text.
Creating a text transcript of a voice recording perfectly fits this definition because it involves converting audio language data into text form — a process handled by speech recognition models. These models analyze the acoustic features of human speech, segment phonemes, identify words, and produce a text transcript. On Azure, this function is implemented using the Azure Cognitive Services Speech-to-Text API, part of the Language and Speech services.
Let’s examine the other options to clarify why they are incorrect:
Computer vision workload: Involves interpreting and analyzing visual data such as images and videos (e.g., object detection, facial recognition). It does not deal with speech or audio.
Knowledge mining workload: Refers to extracting useful information from large amounts of structured and unstructured data using services like Azure Cognitive Search, not transcribing audio.
Anomaly detection workload: Involves identifying unusual patterns in data (e.g., fraud detection or sensor anomalies), unrelated to language or speech.
In summary, when a system creates a text transcript from spoken audio, it is performing a speech recognition task—classified under Natural Language Processing (NLP). This workload helps make spoken content searchable, analyzable, and accessible, aligning with Microsoft’s Responsible AI goal of enhancing accessibility through language understanding.
Question # 28
Match the computer vision service to the appropriate Al workload.
To answer, drag the appropriate service from the column on the left to its workload on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

Full Access
Answer:
Answer: 
Explanation:

This question evaluates understanding of the different Azure AI Computer Vision services and their distinct functionalities, as covered in the Microsoft AI-900 study guide and Microsoft Learn modules under “Describe features of common AI workloads†and “Identify Azure services for computer vision.â€
Azure AI Document Intelligence (formerly known as Form Recognizer):This service is designed to extract structured information from documents, such as forms, receipts, and invoices. It uses optical character recognition (OCR) combined with AI models to detect key-value pairs, tables, and handwritten text. This makes it ideal for automating data entry and digitizing scanned documents. Hence, it matches “Extract information from scanned forms and invoices.â€
Azure AI Vision (formerly Computer Vision):This service provides image and video analysis capabilities. It can detect objects, people, text, and scenes; generate image captions; and extract descriptive tags. It also supports OCR for printed and handwritten text within images. Therefore, it matches “Analyze images and video, and extract descriptions, tags, objects, and text.â€
Azure AI Custom Vision:Custom Vision allows you to train your own image classification and object detection models using your own labeled images. Unlike the general Vision service, Custom Vision lets you build domain-specific models—for example, detecting your company’s products or identifying manufacturing defects. Hence, it matches “Train custom image classification and object detection models by using your own images.â€
These three services complement each other within Azure’s computer vision ecosystem, collectively supporting both general-purpose and specialized AI solutions for visual data analysis.
Question # 29
You need to create a customer support solution to help customers access information. The solution must support email, phone, and live chat channels. Which type of Al solution should you use?
A.
natural language processing (NLP)
B.
computer vision
C.
machine learning
D.
chatbot
Full Access
Answer:
D
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials and Microsoft Learn module “Describe features of common AI workloadsâ€, a chatbot (also known as a conversational AI agent) is a solution designed to interact with users through natural language conversation across multiple channels such as email, phone, webchat, and messaging apps.
Chatbots use Natural Language Processing (NLP) to interpret what users are saying, identify their intent, and provide relevant responses. In Azure, this functionality is implemented using the Azure Bot Service integrated with the Azure Cognitive Service for Language (Question Answering and Language Understanding). The study guide emphasizes that chatbots are used in customer service, information retrieval, and support automation to reduce the workload on human agents and improve response times.
The requirement in this question — supporting email, phone, and live chat channels — aligns exactly with the definition of a conversational AI chatbot, which can operate across multiple communication platforms. Microsoft Learn clearly identifies that chatbots can be deployed to assist customers in retrieving information, answering FAQs, and escalating complex issues when necessary.
The other options are incorrect because:
A. NLP is the underlying technology used by the chatbot but not the solution itself.
B. Computer vision involves analyzing images or videos, which is unrelated to this scenario.
C. Machine learning is a broader AI field and not a specific customer support solution type.
Question # 30
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:

“The Azure OpenAI GPT-3.5 Turbo model can transcribe speech to text.†— NOThis statement is false. The GPT-3.5 Turbo model is a text-based large language model (LLM) designed for natural language understanding and generation, such as answering questions, summarizing text, or writing content. It does not process or transcribe audio input. Speech-to-text capabilities belong to Azure AI Speech Services, specifically the Speech-to-Text API, not Azure OpenAI.
“The Azure OpenAI DALL-E model generates images based on text prompts.†— YESThis statement is true. The DALL-E model, available within Azure OpenAI Service, is a generative AI model that creates original images from natural language descriptions (text prompts). For example, given a prompt like “a futuristic city at sunset,†DALL-E generates a unique, high-quality image representing that concept. This aligns with generative AI workloads in the AI-900 study guide, where DALL-E is specifically mentioned as an image-generation model.
“The Azure OpenAI embeddings model can convert text into numerical vectors based on text similarities.†— YESThis statement is also true. The embeddings model in Azure OpenAI converts text into multi-dimensional numeric vectors that represent semantic meaning. These embeddings enable tasks such as semantic search, recommendations, and text clustering by comparing similarity scores between vectors. Words or phrases with similar meanings have vectors close together in the embedding space.
In summary:
GPT-3.5 Turbo → Text generation (not speech-to-text)
DALL-E → Image generation from text prompts
Embeddings → Convert text into numerical semantic representations
Correct selections: No, Yes, Yes.
Question # 31
Match the Azure Cognitive Services service to the appropriate actions.
To answer, drag the appropriate service from the column on the left to its action on the right. Each service may he used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

Full Access
Answer:
Answer: 
Explanation:

These matches are based on the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore Azure Cognitive Services.â€
Microsoft Azure provides Cognitive Services that enable developers to integrate artificial intelligence capabilities—such as vision, speech, language understanding, and decision-making—into applications without requiring in-depth AI expertise.
Convert a user’s speech to text → Speech ServiceThe Azure Speech Service supports speech-to-text (STT) conversion, which transcribes spoken language into written text. This feature is commonly used in voice assistants, transcription systems, and voice-enabled apps. The service uses advanced speech recognition models to handle different accents, languages, and background noises.
Identify a user’s intent → Language ServiceThe Azure AI Language Service (which includes capabilities from LUIS – Language Understanding) is used to interpret what a user means or wants to achieve based on their words. It identifies intents (the goal or action behind the input) and entities (key pieces of information) from natural language text. This is a key component in conversational AI applications, allowing chatbots and virtual assistants to respond intelligently.
Provide a spoken response to the user → Speech ServiceThe Speech Service also supports text-to-speech (TTS) functionality, which converts textual responses into natural-sounding speech. This enables applications to communicate audibly with users, completing the conversational loop.
Translator Text is not used here because it’s primarily designed for language translation between different languages, not for speech recognition or intent understanding.
Question # 32
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE; Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:
Yes, Yes, No.
According to the Microsoft Azure AI Fundamentals (AI-900) study materials, conversational AI enables applications, websites, and digital assistants to interact with users via natural language. A chatbot is a key conversational AI workload and can be integrated into multiple channels such as web pages, Microsoft Teams, Facebook Messenger, and Cortana using Azure Bot Service and Bot Framework.
“A restaurant can use a chatbot to answer queries through Cortana†— Yes.Azure Bot Service supports multi-channel deployment, which includes Cortana integration. This means the same bot can respond to voice or text input via Cortana, making it a valid use case for a restaurant to provide menu details, reservations, or order tracking through voice-based AI assistants.
“A restaurant can use a chatbot to answer inquiries about business hours from a webpage†— Yes.This is a standard scenario for chatbots embedded on a company website. As per Microsoft Learn’s Describe features of conversational AI module, a chatbot can be added to a website to handle FAQs such as business hours, location, or menu details, thereby improving response time and reducing repetitive human workload.
“A restaurant can use a chatbot to automate responses to customer reviews on an external website†— No.Azure bots and other conversational AI tools cannot automatically interact with or post on external third-party platforms where the business does not control the data or API integration. Automated posting or replying to reviews on external review sites (e.g., Yelp or Google Reviews) would violate both ethical and technical boundaries of responsible AI usage outlined by Microsoft.
Question # 33
In Azure Machine Learning, what are two ensemble methods for combining models in automated machine learning (automated ML)? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A.
stacking
B.
regression
C.
computer vision
D.
voting
E.
classification
Full Access
Answer:
A, D
Question # 34
Match the Azure OpenAI large language model (LLM) process to the appropriate task.
To answer, drag the appropriate process from the column on the left to its task on the right. Each process may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) study material and Azure OpenAI Service documentation, large language models (LLMs) such as GPT are capable of performing multiple natural language processing (NLP) tasks depending on the intent of the prompt. These tasks generally fall into categories like classification, generation, summarization, and translation, each with a distinct purpose and output type.
Classifying – This process involves analyzing text and assigning it to a predefined category or label based on its content. The scenario “Detect the genre of a work of fiction†clearly fits this category. The model must evaluate the text and determine whether it belongs to genres like mystery, romance, or science fiction. This is a classic text classification problem, as the output is a discrete category derived from textual features.
Summarizing – This process means condensing lengthy text into a shorter version that preserves the key information. In the scenario “Create a list of bullet points based on text input,†the model extracts essential information and reformats it as concise bullet points, which is an abstraction form of summarization. Summarization models help users quickly understand the main ideas from long documents, meeting efficiency and readability goals.
Generating – This refers to the LLM’s ability to produce new, creative content based on input instructions. The task “Create advertising slogans from a product description†represents generation because it requires the model to construct original text that didn’t previously exist. Generation tasks showcase the creativity and contextual fluency of models like GPT in marketing and content creation.
Thus, these mappings align directly with the Azure OpenAI LLM capabilities taught in AI-900, linking each NLP process with its most suitable real-world task.
Question # 35
Match the types of computer vision workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once more than once, or not at all.
NOTE: Each correct match is worth one point.

Full Access
Answer:
Answer: 
Explanation:

In the Microsoft Azure AI Fundamentals (AI-900) curriculum, computer vision workloads are grouped into distinct types, each serving a specific purpose. The three major workloads illustrated here are image classification, object detection, and optical character recognition (OCR). Understanding their use cases is essential for correctly mapping them to real-world scenarios.
Generate captions for images → Image classificationThe image classification workload is used to identify the main subject or context of an image and assign descriptive labels. In Microsoft Learn’s “Describe features of computer vision workloads,†image classification models are trained to recognize content (e.g., a cat, a beach, or a city). Caption generation expands on classification results by describing the image’s contents in human-readable language—based on what the model identifies as key visual features.
Extract movie title names from movie poster images → Optical character recognition (OCR)OCR is a vision workload that detects and extracts text from images. Azure AI Vision’s Read API or Document Intelligence OCR models can identify printed or handwritten text within posters, signs, or documents. In this case, the movie title text from a poster is best extracted using OCR.
Locate vehicles in images → Object detectionThe object detection workload identifies multiple objects within an image and provides their locations using bounding boxes. It’s ideal for tasks like counting cars in a parking lot or tracking objects in traffic images.
Question # 36
You build a QnA Maker bot by using a frequently asked questions (FAQ) page.
You need to add professional greetings and other responses to make the bot more user friendly.
What should you do?
A.
Increase the confidence threshold of responses
B.
Enable active learning
C.
Create multi-turn questions
D.
Add chit-chat
Full Access
Answer:
D
Explanation:
According to the Microsoft Learn module “Build a QnA Maker knowledge baseâ€, QnA Maker allows developers to create bots that answer user queries based on documents like FAQs or manuals. To make a bot more natural and conversational, Microsoft provides a “chit-chat†feature — a prebuilt, professionally written set of responses to common conversational phrases such as greetings (“Helloâ€), small talk (“How are you?â€), and polite phrases (“Thank youâ€).
Adding chit-chat improves user experience by making the bot sound friendlier and more human-like. It doesn’t alter the main Q & A logic but enhances the bot’s tone and responsiveness.
The other options are not correct:
A. Increase the confidence threshold makes the bot more selective in responses but doesn’t add new conversational features.
B. Enable active learning improves knowledge base accuracy over time through user feedback.
C. Create multi-turn questions adds conversational flow for related topics but doesn’t add greetings or casual dialogue.
Thus, to make the bot more personable, the correct action is to Add chit-chat.
[Reference:Microsoft Learn – Add chit-chat to a QnA Maker knowledge base, , , ]
Question # 37
You have a database that contains a list of employees and their photos.
You are tagging new photos of the employees.
For each of the following statements select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:

These answers are derived from the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore computer vision in Microsoft Azure.†The Azure Face service, part of Azure Cognitive Services, provides advanced facial recognition capabilities including detection, verification, identification, grouping, and similarity analysis.
Let’s analyze each statement:
“The Face service can be used to group all the employees who have similar facial characteristics.†→ YesThe Face service supports a grouping function that automatically organizes a collection of unknown faces into groups based on visual similarity. It doesn’t require labeled data; instead, it identifies clusters of similar-looking faces. This is particularly useful when building or validating datasets of people.
“The Face service will be more accurate if you provide more sample photos of each employee from different angles.†→ YesAccording to Microsoft documentation, model accuracy improves when you provide multiple high-quality images of each person under different conditions—such as varying lighting, poses, and angles. This diversity allows the service to better learn unique facial characteristics and improves recognition reliability, especially for identification and verification tasks.
“If an employee is wearing sunglasses, the Face service will always fail to recognize the employee.†→ NoThis is incorrect. While occlusions (like sunglasses or hats) can reduce accuracy, the service may still recognize the person depending on how much of the face remains visible. Microsoft Learn explicitly notes that partial occlusion affects recognition confidence but does not guarantee failure.
In conclusion, the Face service can group similar faces (Yes), become more accurate with diverse samples (Yes), and still recognize partially covered faces though with lower confidence (No). These principles align directly with the Face API’s core functions and AI-900 learning objectives regarding computer vision and responsible AI-based facial recognition.
Question # 38
What is an example of unsupervised machine learning?
A.
classification
B.
clustering
C.
regression
Full Access
Answer:
B
Explanation:
In unsupervised machine learning, the algorithm learns patterns or structure within data without pre-labeled outputs or target values. The primary goal is to discover hidden relationships or group similar data points automatically. The Microsoft Azure AI Fundamentals (AI-900) study materials identify clustering as the key example of unsupervised learning.
In clustering, algorithms such as K-means, hierarchical clustering, or DBSCAN group data based on feature similarity. For example, a business may cluster customers by purchase behavior to discover natural customer segments without prior category labels. The model finds inherent patterns within the data rather than being told what to predict.
By contrast, classification and regression are supervised learning techniques. In supervised learning, the algorithm is trained using labeled data where correct outputs are already known. Therefore, the correct answer is B. Clustering, as it best represents unsupervised learning in Azure AI-900 principles.
Question # 39
Which feature of the Azure Al Language service should you use to automate the masking of names and phone numbers in text data?
A.
Personally Identifiable Information (Pll) detection
B.
entity linking
C.
custom text classification
D.
custom named entity recognition (NER)
Full Access
Answer:
A
Explanation:
The correct answer is A. Personally Identifiable Information (PII) detection.
In the Azure AI Language service, PII detection is a built-in feature designed to automatically identify and redact sensitive or confidential information from text data. According to the Microsoft Learn module “Identify capabilities of Azure AI Language†and the AI-900 study guide, this capability can detect personal data such as names, phone numbers, email addresses, credit card numbers, and other identifiers.
When applied, the service scans input text and either masks or removes these PII elements based on configurable parameters, ensuring compliance with data privacy regulations like GDPR or HIPAA.
For example, if a document contains “John Doe’s phone number is 555-123-4567,†PII detection can return “******’s phone number is ***********,†thereby preventing exposure of sensitive personal details.
Option analysis:
A. Personally Identifiable Information (PII) detection: ✅ Correct. It identifies and masks sensitive data in text.
B. Entity linking: Connects recognized entities to known data sources like Wikipedia; not used for redaction.
C. Custom text classification: Classifies text into predefined categories; not designed for masking personal data.
D. Custom named entity recognition (NER): Detects domain-specific entities you define but doesn’t automatically mask them.
Therefore, to automate masking of names and phone numbers, the appropriate Azure AI Language feature is PII detection.
Question # 40
You are designing a system that will generate insurance quotes automatically.
Match the Microsoft responsible Al principles to the appropriate requirements.
To answer, drag the appropriate principle from the column on the left to its requirement on the right Each principle may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

Full Access
Answer:
Answer: 
Explanation:

Microsoft’s Responsible AI principles are the foundation for developing and deploying ethical and trustworthy AI systems. The six key principles are Fairness, Reliability and Safety, Privacy and Security, Inclusiveness, Transparency, and Accountability. Each principle guides specific practices for ensuring AI systems operate responsibly in real-world applications like automated insurance quoting systems.
Transparency – This principle ensures that the AI’s decisions can be understood and explained. Recording the decision-making process and enabling staff to trace how a quote was generated aligns with transparency. It allows stakeholders to interpret the reasoning behind model outputs, ensuring that the AI behaves predictably and ethically.
Privacy and Security – This principle focuses on protecting personal data and ensuring that sensitive information is handled responsibly. Limiting access to customer data only to authorized personnel maintains compliance with privacy laws (like GDPR) and safeguards against misuse. Microsoft emphasizes that AI systems should maintain strict control over data visibility and integrity.
Inclusiveness – This principle ensures that AI systems are accessible to all users, including people with disabilities. By supporting screen readers and assistive technologies, the system ensures equal access to information and services for every customer. Inclusiveness prevents discrimination and promotes accessibility, both of which are central to Microsoft’s Responsible AI strategy.
Thus, the correct mapping of principles is:
Decision process → Transparency
Personal information visibility → Privacy and Security
Accessibility via screen readers → Inclusiveness.
Question # 41
You plan to build a conversational Al solution that can be surfaced in Microsoft Teams. Microsoft Cortana, and Amazon Alexa. Which service should you use?
A.
Azure Bot Service
B.
Azure Cognitive Search
C.
Language service
D.
Speech
Full Access
Answer:
A
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Describe features of conversational AI workloads on Azure,†the Azure Bot Service is the dedicated Azure service for building, connecting, deploying, and managing conversational AI experiences across multiple channels — such as Microsoft Teams, Cortana, and Amazon Alexa.
The Azure Bot Service integrates with the Bot Framework SDK to design intelligent chatbots that can communicate with users in natural language. It also connects seamlessly with other Azure Cognitive Services, such as Language Service (LUIS) for intent understanding and Speech Service for voice input/output.
The question specifies that the conversational AI must be accessible through multiple platforms, including Microsoft Teams, Cortana, and Alexa. Azure Bot Service supports this multi-channel communication model out of the box, allowing developers to configure a single bot that interacts through many endpoints simultaneously.
Other options:
B. Azure Cognitive Search: Used for information retrieval and knowledge mining, not conversational AI.
C. Language Service: Provides natural language understanding, key phrase extraction, sentiment analysis, etc., but doesn’t handle multi-channel communication.
D. Speech: Provides speech-to-text and text-to-speech conversion but is not a chatbot platform.
Therefore, the best solution for building and deploying a multi-channel conversational AI system is Azure Bot Service, as clearly defined in Microsoft’s AI-900 learning content.
Question # 42
You have an Azure Machine Learning model that uses clinical data to predict whether a patient has a disease.
You clean and transform the clinical data.
You need to ensure that the accuracy of the model can be proven.
What should you do next?
A.
Train the model by using the clinical data.
B.
Split the clinical data into Two datasets.
C.
Train the model by using automated machine learning (automated ML).
D.
Validate the model by using the clinical data.
Full Access
Answer:
B
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn modules on machine learning concepts, ensuring that the accuracy of a predictive model can be proven requires data partitioning—specifically splitting the available data into training and testing datasets. This is a foundational concept in supervised machine learning.
When you split the data, typically about 70–80% of the dataset is used for training the model, while the remaining 20–30% is used for testing (or validation). The reason behind this approach is to ensure that the model’s performance metrics—such as accuracy, precision, recall, and F1-score—are evaluated on data the model has never seen before. This prevents overfitting and allows you to demonstrate that the model generalizes well to new, unseen data.
In the AI-900 Microsoft Learn content under “Describe the machine learning processâ€, it is explained that after cleaning and transforming the data, the next essential step is data splitting to “evaluate model performance objectively.†By keeping training and testing data separate, you can prove the reliability and accuracy of the model’s predictions, which is particularly crucial in sensitive domains like clinical or healthcare analytics, where decision transparency and validation are vital.
Option A (Train the model by using the clinical data) is incorrect because you should not train and evaluate on the same data—it would lead to biased results.
Option C (Train the model using automated ML) is incorrect because automated ML is a method for training and tuning, but it doesn’t inherently prove accuracy.
Option D (Validate the model by using the clinical data) is also incorrect if you use the same dataset for validation and training—it would not prove true accuracy.
Therefore, per Microsoft’s official AI-900 study content, the verified correct answer is B. Split the clinical data into two datasets.
Question # 43
Match the principles of responsible AI to appropriate requirements.
To answer, drag the appropriate principles from the column on the left to its requirement on the right. Each principle may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify guiding principles for responsible AIâ€, responsible AI is built upon six foundational principles: Fairness, Reliability and Safety, Privacy and Security, Inclusiveness, Transparency, and Accountability. Each principle serves to guide the ethical design, deployment, and management of artificial intelligence systems.
Fairness – This principle ensures that AI systems treat all people fairly and do not discriminate based on personal attributes such as gender, race, or age. The Microsoft Learn content emphasizes that “AI systems should treat everyone fairly†and that organizations must evaluate datasets and model outputs for bias. In this scenario, “The system must not discriminate based on gender, race†clearly aligns with Fairness because it directly addresses equitable treatment and unbiased decision-making.
Privacy and Security – Microsoft’s responsible AI framework stresses that “AI systems must be secure and respect privacy.†This means personal data should be safeguarded, processed lawfully, and visible only to authorized users. The statement “Personal data must be visible only to approved users†reflects the importance of protecting sensitive information and controlling access—precisely the intent of the Privacy and Security principle.
Transparency – Transparency refers to ensuring that users understand how AI systems operate and make decisions. Microsoft notes that “AI systems should be understandable and users should be able to know why decisions are made.†The requirement “Automated decision-making processes must be recorded so that approved users can identify why a decision was made†directly supports this principle. Transparency promotes trust and accountability by documenting the reasoning behind AI outputs.
Reliability and Safety, though another core principle, does not directly relate to any of the provided statements in this question.
Question # 44
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:
validation.
In the Microsoft Azure AI Fundamentals (AI-900) study materials, a key concept in machine learning model development is splitting data into subsets for training, validation, and testing. A randomly extracted subset of data from a dataset is most commonly used for validation — that is, for evaluating the performance of the model during or after training.
Here’s how this process works:
Training set – This portion of the dataset is used to train the machine learning model. The model learns patterns, relationships, and parameters from this data.
Validation set – This is a randomly selected subset (separate from training data) used to fine-tune model hyperparameters and evaluate how well the model generalizes to unseen data. It helps detect overfitting — when the model performs well on training data but poorly on new data.
Test set – A final, untouched dataset used to measure the model’s real-world performance after all training and tuning are complete.
By reserving a random subset for validation, data scientists ensure that the model’s performance metrics reflect generalization, not memorization of the training data.
Let’s review the incorrect options:
Algorithms – These are the mathematical frameworks or methods used to build models (e.g., decision trees, neural networks). They are not data subsets.
Features – These are input variables (attributes) used by the model, not randomly selected data subsets.
Labels – These are target values or outcomes the model predicts; again, not data subsets.
Therefore, in alignment with Azure AI-900’s machine learning fundamentals, the correct completion is:
✅ “A randomly extracted subset of data from a dataset is commonly used for validation of the model.â€
Question # 45
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

The correct completion of the sentence is:
“The interactive answering of questions entered by a user as part of an application is an example of natural language processing.â€
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials, Natural Language Processing (NLP) is a branch of Artificial Intelligence that focuses on enabling computers to understand, interpret, and respond to human language in a way that is both meaningful and useful. It is one of the key AI workloads described in the “Describe features of common AI workloads†module on Microsoft Learn.
When a user types a question into an application and the system responds interactively — such as in a chatbot, Q & A system, or virtual assistant — this process requires language understanding. NLP allows the system to process the input text, determine user intent, extract relevant entities, and generate an appropriate response. This is the foundational capability behind services such as Azure Cognitive Service for Language, Language Understanding (LUIS), and QnA Maker (now integrated as Question Answering in the Language service).
Microsoft’s study guide explains that NLP workloads include the following key scenarios:
Language understanding: Determining intent and context from text or speech.
Text analytics: Extracting meaning, key phrases, sentiment, or named entities.
Conversational AI: Powering bots and virtual agents to interact using natural language.These systems rely on NLP models to analyze user inputs and respond accordingly.
In contrast:
Anomaly detection identifies data irregularities.
Computer vision analyzes images or video.
Forecasting predicts future values based on historical data.
Therefore, based on the AI-900 official materials, the interactive answering of user questions through an application clearly falls under Natural Language Processing (NLP).
Question # 46
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:

Box 1: Yes
Automated machine learning, also referred to as automated ML or AutoML, is the process of automating the time consuming, iterative tasks of machine learning model development. It allows data scientists, analysts, and developers to build ML models with high scale, efficiency, and productivity all while sustaining model quality.
Box 2: No
Box 3: Yes
During training, Azure Machine Learning creates a number of pipelines in parallel that try different algorithms and parameters for you. The service iterates through ML algorithms paired with feature selections, where each iteration produces a model with a training score. The higher the score, the better the model is considered to " fit " your data. It will stop once it hits the exit criteria defined in the experiment.
Box 4: No
Apply automated ML when you want Azure Machine Learning to train and tune a model for you using the target metric you specify.
The label is the column you want to predict.
[Reference:, https://azure.microsoft.com/en-us/services/machine-learning/automatedml/#features, , , , , ]
Question # 47
You are processing photos of runners in a race.
You need to read the numbers on the runners’ shirts to identity the runners in the photos.
Which type of computer vision should you use?
A.
facial recognition
B.
optical character recognition (OCR)
C.
semantic segmentation
D.
object detection
Full Access
Answer:
B
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of computer vision workloadsâ€, Optical Character Recognition (OCR) is a core capability within the computer vision domain that enables systems to detect and extract text from images or documents. OCR technology can identify printed or handwritten characters in photographs, scanned documents, or camera feeds, and convert them into machine-readable text.
In this scenario, the task is to read the numbers on runners’ shirts in race photos. These numbers are textual or numeric characters embedded within images. OCR is specifically designed for this purpose — to locate and recognize characters within visual data and convert them into usable text. Once extracted, those numbers can be cross-referenced with a database to identify each runner.
Let’s analyze why the other options are incorrect:
A. Facial recognition focuses on identifying individuals based on unique facial features, not reading text or numbers.
C. Semantic segmentation classifies each pixel of an image into categories (for example, separating road, sky, and people), but it doesn’t read text.
D. Object detection identifies and locates objects within an image (such as detecting people or vehicles) but does not extract readable text or numbers.
Therefore, since the task involves reading textual or numeric content from an image, the appropriate type of computer vision to use is Optical Character Recognition (OCR).
[Reference:Microsoft Learn – Identify features and uses of computer vision in Azure AI services (Cognitive Services – Optical Character Recognition)., , , ]
Question # 48
What are two tasks that can be performed by using computer vision? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A.
Predict stock prices.
B.
Detect brands in an image.
C.
Detect the color scheme in an image
D.
Translate text between languages.
E.
Extract key phrases.
Full Access
Answer:
B, C
Explanation:
According to the Microsoft Azure AI Fundamentals study guide and Microsoft Learn module “Identify features of computer vision workloadsâ€, computer vision is an AI workload that allows systems to interpret and understand visual information from the world, such as images and videos.
Computer vision tasks typically include:
Object detection and image classification (e.g., detecting brands, logos, or items in images)
Image analysis (e.g., identifying colors, patterns, or visual features)
Face detection and recognition
Optical Character Recognition (OCR) for reading text in images
Therefore, both detecting brands and detecting color schemes in an image are clear examples of computer vision tasks because they involve analyzing visual content.
In contrast:
A. Predict stock prices → Regression task, not vision-based.
D. Translate text between languages → Natural language processing (NLP).
E. Extract key phrases → NLP as well.
Thus, the correct computer vision tasks are B and C.
[Reference:Microsoft Learn – Identify features and uses of computer vision in Azure AI services, , , , ]
Question # 49
Match the principles of responsible AI to the appropriate descriptions.
To answer, drag the appropriate principle from the column on the left to its description on the right. Each principle may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

Full Access
Answer:
Answer: 
Explanation:

The correct answers are derived from the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Identify guiding principles for responsible AI.â€
Microsoft defines six core principles of Responsible AI:
Fairness
Reliability and safety
Privacy and security
Inclusiveness
Transparency
Accountability
Each principle addresses a key ethical and operational requirement for developing and deploying trustworthy AI systems.
Reliability and safety – “AI systems must consistently operate as intended, even under unexpected conditions.â€This principle ensures that AI models are dependable, robust, and perform accurately under diverse circumstances. Microsoft emphasizes that systems should be thoroughly tested and monitored to guarantee predictable behavior, prevent harm, and maintain safety. A reliable AI solution should continue to function properly when faced with unusual or noisy inputs, and fail safely when issues arise. This principle focuses on stability, testing, and dependable performance.
Privacy and security – “AI systems must protect and secure personal and business information.â€This principle ensures that AI systems comply with data privacy laws and ethical standards. It protects users’ sensitive data against unauthorized access and misuse. Microsoft highlights that organizations must implement strong encryption, data anonymization, and access control mechanisms to maintain confidentiality. Protecting user data is essential to building trust and compliance with global standards like GDPR.
Other principles such as fairness and inclusiveness apply to ensuring equitable and accessible AI, but they do not directly relate to system operation or information protection.
✅ Final Answers:
“Operate as intended†→ Reliability and safety
“Protect and secure information†→ Privacy and security
Question # 50
You have a dataset that contains information about taxi journeys that occurred during a given period.
You need to train a model to predict the fare of a taxi journey.
What should you use as a feature?
A.
the number of taxi journeys in the dataset
B.
the trip distance of individual taxi journeys
C.
the fare of individual taxi journeys
D.
the trip ID of individual taxi journeys
Full Access
Answer:
B
Explanation:
The label is the column you want to predict. The identified Features are the inputs you give the model to predict the Label.
Example:
The provided data set contains the following columns:
vendor_id: The ID of the taxi vendor is a feature.
rate_code: The rate type of the taxi trip is a feature.
passenger_count: The number of passengers on the trip is a feature.
trip_time_in_secs: The amount of time the trip took. You want to predict the fare of the trip before the trip is completed. At that moment, you don ' t know how long the trip would take. Thus, the trip time is not a feature and you ' ll exclude this column from the model.
trip_distance: The distance of the trip is a feature.
payment_type: The payment method (cash or credit card) is a feature.
fare_amount: The total taxi fare paid is the label.
[Reference:, https://docs.microsoft.com/en-us/dotnet/machine-learning/tutorials/predict-prices, , , , , ]
Question # 51
Match the Microsoft guiding principles for responsible AI to the appropriate descriptions.
To answer, drag the appropriate principle from the column on the left to its description on the right. Each principle may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
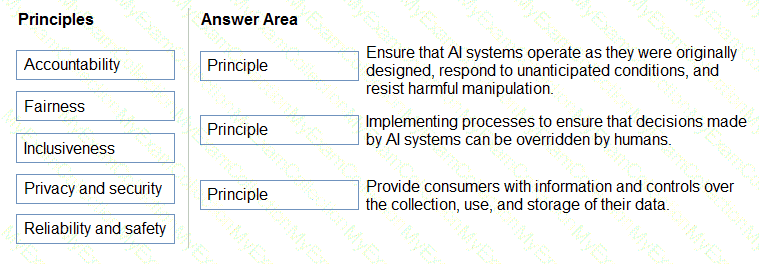
Full Access
Answer:
Answer: 
Explanation:
Box 1: Reliability and safety
To build trust, it ' s critical that AI systems operate reliably, safely, and consistently under normal circumstances and in unexpected conditions. These systems should be able to operate as they were originally designed, respond safely to unanticipated conditions, and resist harmful manipulation.
Box 2: accountability
Box 3: Privacy and security
As AI becomes more prevalent, protecting privacy and securing important personal and business information is becoming more critical and complex. With AI, privacy and data security issues require especially close attention because access to data is essential for AI systems to make accurate and informed predictions and decisions about people. AI systems must comply with privacy laws that require transparency about the collection, use, and storage of data and mandate that consumers have appropriate controls to choose how their data is used
https://docs.microsoft.com/en-us/learn/modules/responsible-ai-principles/4-guiding-principles
Question # 52
You are developing a Chabot solution in Azure.
Which service should you use to determine a user’s intent?
A.
Translator
B.
Azure Cognitive Search
C.
Speech
D.
Language
Full Access
Answer:
D
Explanation:
In Azure, the Language service unifies several natural language capabilities, including LUIS, QnA Maker, and Text Analytics, into one comprehensive service. To determine a user’s intent in a chatbot, you use the Conversational Language Understanding (CLU) feature of the Language service, which is the evolution of LUIS.
CLU helps chatbots and applications comprehend natural language input by identifying the intent (the purpose of the user’s statement) and extracting entities (important details). For example, when a user types “Book a meeting for tomorrow,†the model recognizes the intent (BookMeeting) and the entity (tomorrow).
The other options do not determine intent:
Translator (A) is used for language translation.
Azure Cognitive Search (B) retrieves documents based on search queries.
Speech (C) converts audio to text but doesn’t analyze meaning.
Thus, to determine a user’s intent in a chatbot scenario, the correct service is D. Language.
[Reference:Microsoft Learn – “Build conversational language understanding models with Azure Language service.â€, , , , , ]
Question # 53
You plan to develop an Al application that will read the license plates of motor vehicles by using Microsoft Foundry. What should you use to develop the application?
A.
Copilot for Microsoft 365
B.
Microsoft Visual Studio Code
C.
GitHub Actions
D.
Azure Al Studio
Full Access
Answer:
D
Question # 54
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:
Yes, Yes, and No.
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn modules under the topic “Describe features of common AI workloadsâ€, conversational AI solutions like chatbots are used to automate and enhance customer interactions. A chatbot is an AI service capable of understanding user inputs (text or voice) and providing appropriate responses, often integrated into websites, mobile apps, or messaging platforms.
A restaurant can use a chatbot to empower customers to make reservations using a website or an app – Yes.This statement is true because conversational AI is designed to handle structured tasks such as booking, scheduling, and information retrieval. Chatbots built with Azure Bot Service can connect to backend systems (like a reservation database) to let customers make or modify reservations through a chat interface. The AI-900 study guide explicitly notes that chatbots can help businesses “automate processes such as booking or reservations†to improve efficiency and customer experience.
A restaurant can use a chatbot to answer inquiries about business hours from a webpage – Yes.This is also true. Chatbots can be trained using QnA Maker (now integrated into Azure AI Language) or Azure Cognitive Services for Language to answer common customer questions. FAQs such as opening hours, menu details, and directions are ideal for chatbot automation, as outlined in the AI-900 modules discussing customer support automation.
A restaurant can use a chatbot to automate responses to customer reviews on an external website – No.This is not a typical chatbot use case taught in AI-900. Chatbots are meant for direct interactions within controlled channels, such as a company’s own website or messaging app. Managing and posting responses to reviews on external platforms (like Yelp or Google Reviews) would involve policy restrictions, authentication issues, and reputational risk. The AI-900 course specifies that responsible AI usage requires maintaining human oversight in public-facing communications that influence brand image.
Question # 55
Select the answer that correctly completes the sentence.
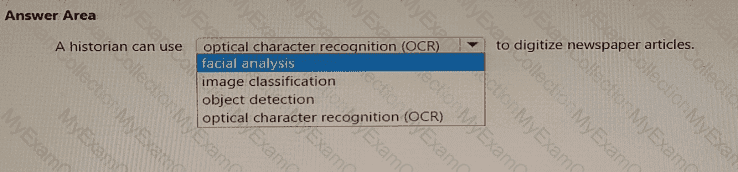
Full Access
Answer:
Answer: 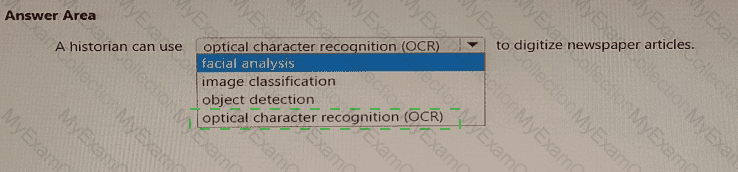
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore computer vision in Microsoft Azure,†Optical Character Recognition (OCR) is a computer vision capability that detects and extracts printed or handwritten text from images or scanned documents and converts it into machine-readable digital text.
In this scenario, a historian wants to digitize newspaper articles — which means converting physical or scanned images of printed text into digital text for easier searching, archiving, and analysis. This is exactly the function of OCR. By using OCR, the historian can take photos or scans of old newspapers and extract the words into editable digital documents, preserving valuable historical information.
OCR is a key feature of the Azure Computer Vision service, which provides capabilities such as:
Extracting text from images or PDFs.
Reading both printed and handwritten text in multiple languages.
Converting physical documents into searchable digital files.
Let’s examine the incorrect options:
Facial analysis: Detects facial features, age, gender, and emotions — unrelated to text extraction.
Image classification: Identifies what an image contains (e.g., “dog,†“car,†or “buildingâ€) but doesn’t extract text.
Object detection: Identifies and locates objects within an image using bounding boxes, not suitable for text recognition.
Therefore, to digitize newspaper articles and convert printed words into editable digital text, the correct technology to use is Optical Character Recognition (OCR), provided by the Azure Computer Vision API.
✅ Final Answer: optical character recognition (OCR)
Question # 56
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
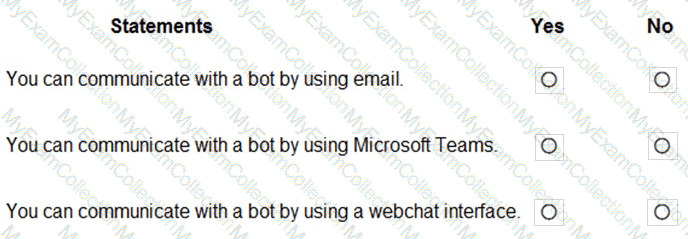
Full Access
Answer:
Answer: 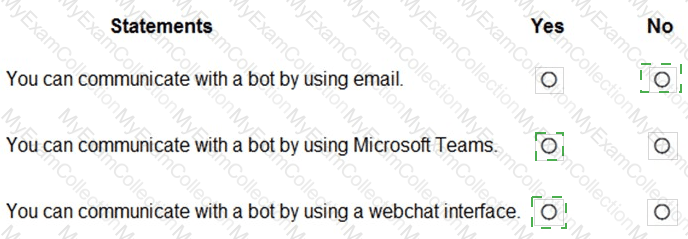
Explanation:
 You can communicate with a bot by using email → No
 You can communicate with a bot by using Microsoft Teams → Yes
 You can communicate with a bot by using a webchat interface → Yes
These answers are based on the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore conversational AI in Microsoft Azure.â€
The Azure Bot Service allows developers to build, test, deploy, and manage intelligent chatbots that can interact with users through various channels. Channels are communication platforms or interfaces that connect users to bots. Once a bot is built and published through the Azure Bot Service, it can be connected to multiple channels such as Microsoft Teams, webchat, Skype, Facebook Messenger, Direct Line, Slack, and others.
Let’s evaluate each statement:
You can communicate with a bot by using email → NoAzure Bot Service does not support direct interaction via email as a channel. Bots are designed for real-time or conversational interactions through messaging or voice-based platforms, not asynchronous email communication.
You can communicate with a bot by using Microsoft Teams → YesMicrosoft Teams is one of the primary channels supported by Azure Bot Service. Bots can be integrated directly into Teams to handle chat-based conversations, provide information, automate workflows, or assist users interactively within Teams.
You can communicate with a bot by using a webchat interface → YesThe Web Chat channel is another core feature of Azure Bot Service. It allows embedding the bot into a website or web application using the Web Chat control or the Direct Line API, enabling users to chat directly from a browser interface.
In summary, Azure Bot Service supports real-time conversational interfaces like Teams and webchat, but not email.
Question # 57
Which natural language processing feature can be used to identify the main talking points in customer feedback surveys?
A.
language detection
B.
translation
C.
entity recognition
D.
key phrase extraction
Full Access
Answer:
D
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Explore natural language processing (NLP) in Azureâ€, key phrase extraction is a core feature of the Azure AI Language Service that enables you to automatically identify the most important ideas or topics discussed in a body of text.
When analyzing customer feedback surveys, key phrase extraction helps summarize the main talking points or recurring themes by detecting significant words and phrases. For instance, if multiple customers write comments like “The checkout process is slow†or “Website speed could be improved,†the model may extract key phrases such as “checkout process†and “website speed.†This allows businesses to quickly understand the most common subjects without manually reading each response.
Let’s review the other options:
A. Language detection: Determines the language of the text (e.g., English, French, or Spanish) but does not identify main ideas.
B. Translation: Converts text from one language to another using Azure Translator; it does not summarize or extract key information.
C. Entity recognition: Identifies named entities such as people, organizations, locations, or dates. While useful for identifying specific details, it does not capture general topics or overall discussion points.
Therefore, the appropriate NLP feature for identifying main topics or themes within textual data such as survey responses is Key Phrase Extraction.
This capability is part of the Azure AI Language Service and is commonly used in sentiment analysis pipelines, customer feedback analytics, and business intelligence workflows to summarize large text datasets efficiently.
Question # 58
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of the Computer Vision and Custom Vision servicesâ€, the Custom Vision service is used to train, deploy, and improve custom image classification and object detection models using your own labeled data.
Multilabel or Multiclass Selection – NOThe statement is false because the Multilabel or Multiclass choice applies only to image classification models, not object detection models. In image classification, “Multiclass†means one label per image, while “Multilabel†means multiple labels per image. In contrast, object detection models identify and locate multiple objects in an image using bounding boxes; thus, this classification-type selection does not apply.
Object Detection Locates Content in an Image – YESThis statement is true. The object detection functionality in Custom Vision is designed to both identify what objects appear in an image and determine their location through bounding box coordinates. For example, a model could detect and locate multiple products on a store shelf. Microsoft documentation describes object detection as “identifying the presence and location of objects in an image.â€
Predefined Domains – YESThis statement is true as well. When you create a new Custom Vision project, you must select a domain, which is a predefined optimization setting tailored to specific use cases such as retail, food, landmarks, or general images. These domains are designed to improve model accuracy by applying specialized transfer learning features based on the type of images you will analyze.
In summary:
Classification type (Multilabel/Multiclass): No (only for classification models)
Detect object location: Yes
Choose predefined domain: Yes
Question # 59
What are three Microsoft guiding principles for responsible AI? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A.
knowledgeability
B.
decisiveness
C.
inclusiveness
D.
fairness
E.
opinionatedness
F.
reliability and safety
Full Access
Answer:
C, D, F
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Describe features of common AI workloads and considerationsâ€, Microsoft has defined six guiding principles for responsible AI. These principles are intended to ensure that AI systems are developed and deployed in ways that are ethical, transparent, and beneficial to all. The six principles are: Fairness, Reliability and Safety, Privacy and Security, Inclusiveness, Transparency, and Accountability.
Let’s break down the three correct options:
Fairness – Microsoft emphasizes that AI systems should treat all individuals fairly and avoid discrimination against people based on gender, race, age, or other characteristics. Fairness ensures that outcomes and decisions from AI systems are equitable across diverse user groups. In the AI-900 learning materials, fairness is explained as a foundational value that ensures algorithms and models do not introduce or amplify societal bias.
Reliability and Safety – This principle ensures that AI systems function as intended under all expected conditions and that they can handle unexpected inputs safely. Microsoft states that AI should be tested rigorously and validated for reliability before deployment. AI systems must perform consistently and avoid causing harm due to errors or failures.
Inclusiveness – Inclusiveness focuses on empowering everyone and engaging people of all backgrounds. Microsoft’s responsible AI guidance stresses designing AI systems that understand and respect cultural, linguistic, and ability differences to make technology accessible and beneficial to all users.
Options A (knowledgeability), B (decisiveness), and E (opinionatedness) are not part of Microsoft’s Responsible AI principles. These terms do not appear in any Microsoft Learn AI-900 curriculum or official responsible AI documentation.
Thus, based on the verified AI-900 study content and Microsoft’s Responsible AI framework, the correct answer is C. Inclusiveness, D. Fairness, and F. Reliability and Safety.
Question # 60
Stating the source of the data used to train a model is an example of which responsible Al principle?
A.
fairness
B.
transparency
C.
reliability and safety
D.
privacy and security
Full Access
Answer:
B
Explanation:
According to Microsoft’s Responsible AI Principles, Transparency means that AI systems should clearly communicate how they operate, including data sources, limitations, and decision-making processes. Stating the source of data used to train a model helps users understand where the model’s knowledge comes from, enabling informed trust and accountability.
Transparency ensures that organizations disclose relevant details about data collection and model design, especially for compliance, fairness, and reproducibility.
Other options are incorrect:
A. Fairness: Focuses on avoiding bias and ensuring equitable outcomes.
C. Reliability and safety: Ensures AI performs consistently and safely.
D. Privacy and security: Protects user data and maintains confidentiality.
Thus, the principle illustrated by disclosing training data sources is Transparency.
Question # 61
Select the answer that correctly completes the sentence

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify features of Computer Vision workloads on Azureâ€, Object Detection is a specific computer vision capability used to identify and locate multiple types of objects within a single image. Unlike image classification, which assigns one label to an entire image, object detection identifies individual objects, their categories, and their positions using bounding boxes or polygons.
In practical terms, Object Detection combines two key outputs:
Classification – recognizing what the object is (for example, “carâ€, “personâ€, “dogâ€).
Localization – determining where the object appears in the image by drawing bounding boxes around it.
This technology is commonly used in scenarios such as traffic monitoring (detecting vehicles and pedestrians), retail shelf analysis (detecting products and inventory levels), and manufacturing quality control (identifying defective parts).
Microsoft’s Azure Cognitive Services – Custom Vision includes a dedicated Object Detection domain, which allows developers to train custom models to recognize multiple object types within a single image. The service uses deep learning techniques, particularly convolutional neural networks (CNNs), to process pixel patterns and spatial relationships for accurate detection.
For contrast:
Image Classification identifies only the overall category of an image (e.g., “This is a catâ€).
Image Description generates captions summarizing the visual content (e.g., “A cat sitting on a couchâ€).
Optical Character Recognition (OCR) detects and extracts text from images, not physical objects.
Therefore, per the official AI-900 learning content and Azure documentation, when the goal is to identify multiple types of items within a single image, the correct AI workload is Object Detection.
Question # 62
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 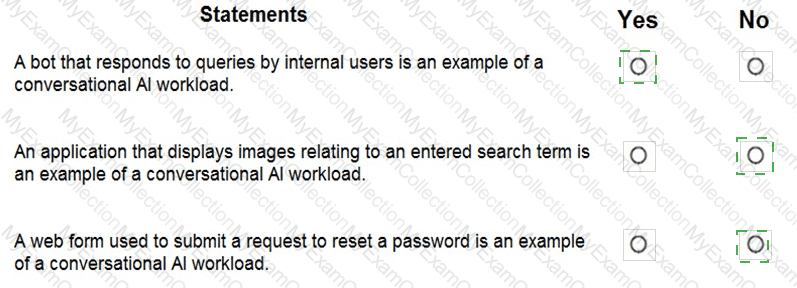
Explanation:
Statements
Yes
No
A bot that responds to queries by internal users is an example of a conversational AI workload.
✅ Yes
An application that displays images relating to an entered search term is an example of a conversational AI workload.
✅ No
A web form used to submit a request to reset a password is an example of a conversational AI workload.
✅ No
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials, conversational AI workloads are those that enable interaction between humans and AI systems through natural language conversation, either by text or speech. These workloads are typically implemented using Azure Bot Service, Azure Cognitive Services for Language, and Azure OpenAI Service. The key characteristic of a conversational AI workload is the presence of dialogue—the AI interprets user intent and provides a meaningful, contextual response in a conversation-like manner.
“A bot that responds to queries by internal users is an example of a conversational AI workload.†→ YESThis fits the definition perfectly. A chatbot that helps employees (internal users) by answering questions about policies, IT issues, or HR procedures is a typical example of conversational AI. It uses natural language understanding to interpret questions and provide automated responses. Microsoft Learn explicitly identifies chatbots as conversational AI solutions designed for both internal and external interactions.
“An application that displays images relating to an entered search term is an example of a conversational AI workload.†→ NOThis is not conversational AI because there is no dialogue or language understanding involved. It is an example of information retrieval or computer vision if it uses image recognition, but not conversation.
“A web form used to submit a request to reset a password is an example of a conversational AI workload.†→ NOA password reset form is a simple UI-driven process that doesn’t require AI or conversational logic. It performs a fixed function based on user input but does not understand or respond to natural language.
Therefore, based on the AI-900 study guide, only the first statement is an example of a conversational AI workload, while the second and third statements are not.
Question # 63
To complete the sentence, select the appropriate option in the answer area.

Full Access
Answer:
Answer: 
Explanation:
Features
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Explore fundamental principles of machine learning,†data values that influence the prediction of a model are called features. In the context of machine learning, a feature is an individual measurable property, attribute, or input variable used by the model to make predictions.
Features are the independent variables that describe the characteristics of the data. For example, in a housing price prediction model, features might include square footage, location, number of bedrooms, and year built. These inputs help the model understand relationships in the data so it can predict the target outcome (the house price).
Microsoft Learn explains that features are the input variables that the algorithm uses to identify patterns and relationships in the training data. During training, the model learns how changes in these features influence the label (also known as the dependent variable or target variable). The label is the value the model tries to predict—such as “price,†“category,†or “yes/no.â€
Here’s how the other options differ:
Dependent variables (labels): These are the outcomes or target values the model predicts, not the inputs.
Identifiers: These are unique keys (like customer ID or transaction ID) used to distinguish records but not to influence predictions.
Labels: As mentioned, labels are the results the model tries to predict.
Therefore, based on the AI-900 learning objectives and Microsoft’s official explanation, the data values that influence the prediction of a model—that is, the input variables that guide the model’s learning—are called features. These features form the foundation of the model’s predictive capabilities and directly impact its accuracy and performance.
Question # 64
To complete the sentence, select the appropriate option in the answer area.

Full Access
Answer:
Answer: 
Explanation:

According to Microsoft’s Responsible AI principles, one of the key guiding values is Reliability and Safety, which ensures that AI systems operate consistently, accurately, and safely under all intended conditions. The AI-900 study materials and Microsoft Learn modules explain that an AI system must be trustworthy and dependable, meaning it should not produce results when the input data is incomplete, corrupted, or significantly outside the expected range.
In the given scenario, the AI system avoids providing predictions when important fields contain unusual or missing values. This behavior demonstrates reliability and safety because it prevents the system from making unreliable or potentially harmful decisions based on bad or insufficient data. Microsoft emphasizes that AI systems must undergo extensive validation, testing, and monitoring to ensure stable performance and predictable outcomes, even when data conditions vary.
The other options do not fit this scenario:
Inclusiveness ensures that AI systems are accessible to and usable by all people, regardless of abilities or backgrounds.
Privacy and Security focuses on protecting user data and ensuring it is used responsibly.
Transparency involves making AI decisions explainable and understandable to humans.
Only Reliability and Safety directly address the concept of an AI system refusing to act or returning an error when it cannot make a trustworthy prediction. This principle helps prevent inaccurate or unsafe outputs, maintaining confidence in the system’s integrity.
Therefore, ensuring an AI system does not produce predictions when input data is incomplete or unusual aligns directly with Microsoft’s Reliability and Safety principle for responsible AI.
Question # 65
You send an image to a Computer Vision API and receive back the annotated image shown in the exhibit.

Which type of computer vision was used?
A.
object detection
B.
semantic segmentation
C.
optical character recognition (OCR)
D.
image classification
Full Access
Answer:
A
Explanation:
Object detection is similar to tagging, but the API returns the bounding box coordinates (in pixels) for each object found. For example, if an image contains a dog, cat and person, the Detect operation will list those objects together with their coordinates in the image. You can use this functionality to process the relationships between the objects in an image. It also lets you determine whether there are multiple instances of the same tag in an image.
The Detect API applies tags based on the objects or living things identified in the image. There is currently no formal relationship between the tagging taxonomy and the object detection taxonomy. At a conceptual level, the Detect API only finds objects and living things, while the Tag API can also include contextual terms like " indoor " , which can ' t be localized with bounding boxes.
[Reference:, https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/concept-object-detection, , , , , ]
Question # 66
In which two scenarios can you use the Azure Al Document Intelligence service (formerly Form Recognizer)? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A.
Extract the invoice number from an invoice.
B.
Identify the retailer from a receipt.
C.
Find images of products in a catalog.
D.
Translate a form from French to English.
Full Access
Answer:
A, B
Explanation:
The Azure AI Document Intelligence service (formerly Form Recognizer) is designed to analyze, extract, and structure data from scanned or digital documents such as invoices, receipts, contracts, and forms. According to the Microsoft Learn module “Extract data from documents with Azure AI Document Intelligenceâ€, the service uses optical character recognition (OCR) and pretrained machine learning models to automatically extract key information.
A. Extract the invoice number from an invoice – YESThe prebuilt invoice model in Document Intelligence can detect and extract key fields such as invoice number, date, total amount, tax, and vendor details from scanned or digital invoices.
B. Identify the retailer from a receipt – YESThe prebuilt receipt model can recognize fields like merchant name (retailer), transaction date, total spent, and tax amount, making this option correct as well.
C. Find images of products in a catalog – NOThis is a computer vision or Custom Vision use case, not a document data extraction task.
D. Translate a form from French to English – NOTranslation involves Azure AI Translator, part of the Language service, not Document Intelligence.
Hence, the correct and Microsoft-verified answers are:
✅ A. Extract the invoice number from an invoice
✅ B. Identify the retailer from a receipt
Question # 67
Select the answer that correctly completes the sentence.
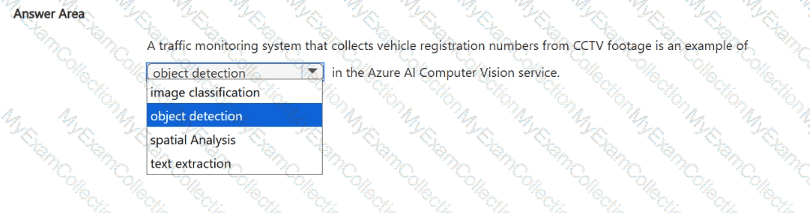
Full Access
Answer:
Answer: 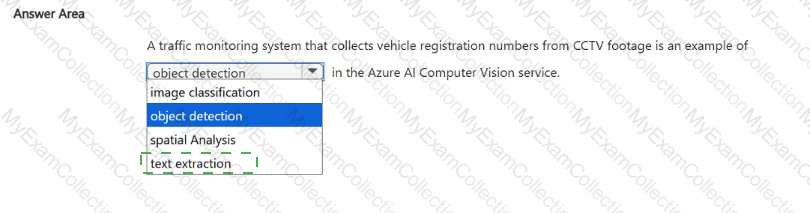
Explanation:
Text extraction.
According to the Microsoft Azure AI Fundamentals (AI-900) study guide and Microsoft Learn documentation for Azure AI Vision (formerly Computer Vision), text extraction—also known as Optical Character Recognition (OCR)—is the computer vision capability that detects and extracts printed or handwritten text from images and video frames.
In this scenario, a traffic monitoring system collects vehicle registration numbers (license plates) from CCTV footage. These registration numbers are alphanumeric text that must be read and converted into digital form for processing, storage, or analysis. The Azure AI Vision service’s OCR (text extraction) feature performs this function. It analyzes each frame from the video feed, detects text regions (the license plates), and converts the visual text into machine-readable text data.
This process is widely used in Automatic Number Plate Recognition (ANPR) systems that support law enforcement, toll booths, and parking management solutions. The OCR model can handle variations in font, lighting, and angle to accurately extract license plate numbers.
The other options describe different vision capabilities:
Image classification assigns an image to a general category (e.g., “car,†“truck,†or “bikeâ€), not text extraction.
Object detection identifies and locates objects in images using bounding boxes (e.g., detecting the car itself), but not the text written on the car.
Spatial analysis tracks people or objects in a defined physical space (e.g., counting individuals entering a building), not reading text.
Therefore, for a traffic monitoring system that identifies vehicle registration numbers from CCTV footage, the most accurate Azure AI Vision capability is Text extraction (OCR).
Question # 68
Match the Azure Al service to the appropriate generative Al capability.
To answer, drag the appropriate service from the column on the left to its capability on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
Full Access
Answer:
Answer: 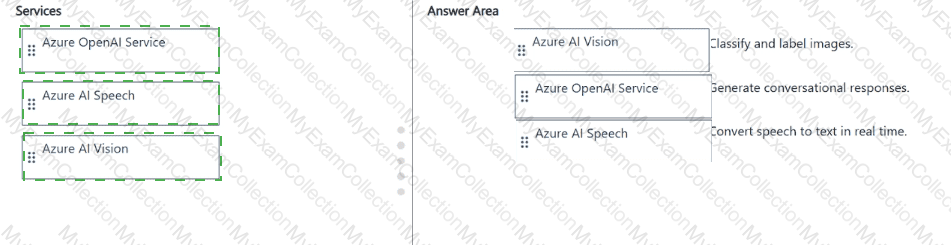
Explanation:

This question maps each Azure AI service to its correct capability based on the Microsoft Azure AI Fundamentals (AI-900) syllabus and Microsoft Learn documentation on Azure Cognitive Services.
Classify and label images → Azure AI VisionAzure AI Vision (formerly Computer Vision) provides capabilities to analyze visual content, detect objects, classify images, and extract information from pictures. It includes object detection, image classification, and tagging, which are core vision tasks. This service enables businesses to build solutions that understand visual input, such as identifying products, reading signs, or detecting faces in images.
Generate conversational responses → Azure OpenAI ServiceAzure OpenAI Service integrates powerful large language models such as GPT-3.5 and GPT-4, capable of generating human-like text responses, summarizations, translations, and dialogues. These models are designed for natural language generation (NLG) and conversational AI, making them ideal for chatbots, virtual agents, and intelligent assistants that produce dynamic, context-aware replies.
Convert speech to text in real time → Azure AI SpeechAzure AI Speech provides speech-to-text capabilities (speech recognition) that convert spoken language into written text instantly. It is commonly used in transcription services, voice command systems, and live captioning applications. Additionally, the Speech service supports text-to-speech (speech synthesis) and speech translation, making it versatile for voice-based AI applications.
By understanding each service’s specialization—Vision for visual data, OpenAI for generative text, and Speech for audio processing—you can correctly match the capabilities.
Question # 69
You use Azure Machine Learning designer to build a model pipeline. What should you create before you can run the pipeline?
A.
a Jupyter notebook
B.
a registered model
C.
a compute resource
Full Access
Answer:
C
Explanation:
Before running a pipeline in Azure Machine Learning Designer, you must have an available compute resource (such as a compute instance or compute cluster). Compute provides the processing power required to train, evaluate, and execute the pipeline’s modules.
Other options:
A. Jupyter notebook – Used for code-first development, not required for Designer pipelines.
B. Registered model – Created after running a pipeline, not before.
Question # 70
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:

The correct answers are based on the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore fundamental principles of machine learning.â€
In supervised machine learning, data is typically divided into three main subsets:
Training set – used to train the model, i.e., to teach the algorithm the patterns and relationships between input features and output labels.
Validation set – used to evaluate the model during training to tune hyperparameters and prevent overfitting.
Test set – used after training to assess the final model’s performance on unseen data.
Let’s analyze each statement in light of these definitions:
“A validation set includes the set of input examples that will be used to train a model.†→ NoThis is incorrect because the training set, not the validation set, contains the input examples used for model training. The validation set is separate from the training data to ensure unbiased evaluation.
“A validation set can be used to determine how well a model predicts labels.†→ YesThis is correct. The validation set helps assess how effectively the model generalizes during training. It measures performance and helps tune model parameters for optimal results.
“A validation set can be used to verify that all the training data was used to train the model.†→ NoThis is false. The validation set is not used to verify the completeness of training data usage. It exists independently to evaluate the model’s performance during training cycles.
According to Microsoft Learn, using a validation set helps ensure that a model generalizes well and avoids overfitting to the training data. It plays a crucial role in refining and optimizing models before final testing.
Question # 71
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE; Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn modules on machine learning concepts, ensuring that the accuracy of a predictive model can be proven requires data partitioning—specifically splitting the available data into training and testing datasets. This is a foundational concept in supervised machine learning.
When you split the data, typically about 70–80% of the dataset is used for training the model, while the remaining 20–30% is used for testing (or validation). The reason behind this approach is to ensure that the model’s performance metrics—such as accuracy, precision, recall, and F1-score—are evaluated on data the model has never seen before. This prevents overfitting and allows you to demonstrate that the model generalizes well to new, unseen data.
In the AI-900 Microsoft Learn content under “Describe the machine learning processâ€, it is explained that after cleaning and transforming the data, the next essential step is data splitting to “evaluate model performance objectively.†By keeping training and testing data separate, you can prove the reliability and accuracy of the model’s predictions, which is particularly crucial in sensitive domains like clinical or healthcare analytics, where decision transparency and validation are vital.
Option A (Train the model by using the clinical data) is incorrect because you should not train and evaluate on the same data—it would lead to biased results.
Option C (Train the model using automated ML) is incorrect because automated ML is a method for training and tuning, but it doesn’t inherently prove accuracy.
Option D (Validate the model by using the clinical data) is also incorrect if you use the same dataset for validation and training—it would not prove true accuracy.
Therefore, per Microsoft’s official AI-900 study content, the verified correct answer is B. Split the clinical data into two datasets.
Question # 72
You have the process shown in the following exhibit.
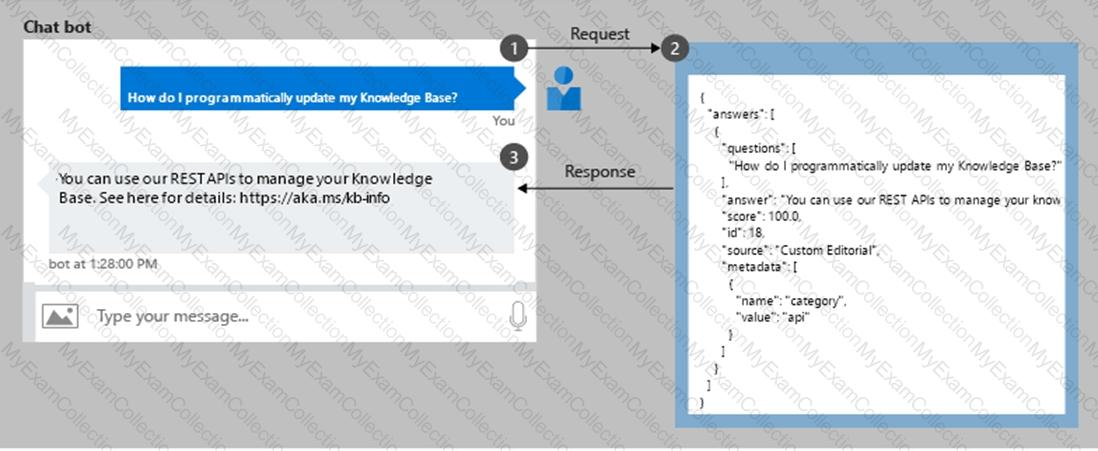
Which type AI solution is shown in the diagram?
A.
a sentiment analysis solution
B.
a chatbot
C.
a machine learning model
D.
a computer vision application
Full Access
Answer:
B
Question # 73
You are building an AI system.
Which task should you include to ensure that the service meets the Microsoft transparency principle for responsible AI?
A.
Ensure that all visuals have an associated text that can be read by a screen reader.
B.
Enable autoscaling to ensure that a service scales based on demand.
C.
Provide documentation to help developers debug code.
D.
Ensure that a training dataset is representative of the population.
Full Access
Answer:
C
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and Microsoft Learn module “Describe principles of responsible AIâ€, the transparency principle ensures that AI systems are understandable, explainable, and well-documented so that users, developers, and stakeholders can know how the system operates and makes decisions. Transparency involves clear communication, documentation, and interpretability.
Microsoft defines transparency as the responsibility to make sure that people understand how AI systems function, their limitations, and how decisions are made. For developers, this means providing detailed documentation and model interpretability tools so others can inspect, debug, and understand the AI model’s behavior. For users, it means ensuring that the purpose, capabilities, and limitations of the AI system are clearly explained.
Providing documentation to help developers debug and understand how a service works directly aligns with this transparency principle. It ensures that the system’s logic and behavior are open to inspection and that any unintended consequences can be identified and corrected. Transparency also builds trust in AI solutions by enabling accountability and oversight.
Let’s analyze the other options:
A. Ensure that all visuals have an associated text that can be read by a screen reader – This supports inclusiveness, not transparency, as it focuses on accessibility for all users.
B. Enable autoscaling to ensure that a service scales based on demand – This is related to system performance and scalability, not responsible AI.
D. Ensure that a training dataset is representative of the population – This supports fairness, as it prevents bias and ensures equitable outcomes.
Therefore, based on the official AI-900 training content and Microsoft’s Responsible AI framework (which includes fairness, reliability, privacy, inclusiveness, transparency, and accountability), the correct answer is C. Provide documentation to help developers debug code, because this directly promotes transparency in how the AI system operates and communicates its inner workings
Question # 74
To complete the sentence, select the appropriate option in the answer area.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Describe core concepts of machine learning on Azureâ€, labeling is the process of assigning correct output values (labels) to training data before model training. In supervised learning, every input in the dataset must be paired with its corresponding output so the algorithm can learn the relationship between the two.
In this scenario, the task is to assign classes to images before training a classification model—for example, marking images as “cat,†“dog,†or “bird.†This process defines the target variable (label) that the model will later predict. During training, the classification model uses these labeled examples to learn patterns and distinguish between categories.
Microsoft’s official materials clearly define labeling as:
“The process of tagging data with the correct answer so that the model can learn to make predictions.â€
Labeling is a crucial early step in the machine learning lifecycle, especially for image classification and natural language processing (NLP) tasks. Without accurate labels, the model cannot learn correctly and its predictions will be unreliable.
Let’s briefly clarify why the other options are incorrect:
Evaluation refers to testing the model after training to measure accuracy or performance using metrics like precision, recall, or F1 score.
Feature engineering involves creating or selecting the most relevant input features from raw data but does not involve tagging output labels.
Hyperparameter tuning adjusts parameters (like learning rate or depth of a tree) to optimize model performance after labeling and training have begun.
Thus, assigning classes to images prior to model training is definitively a Labeling task.
Question # 75
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:
When building a K-means clustering model, all features (variables) used in the model must be numeric in nature. According to the Microsoft Azure AI Fundamentals (AI-900) study materials and standard machine learning theory, K-means clustering is an unsupervised learning algorithm that groups data points into clusters based on their similarity — specifically by minimizing the Euclidean distance between data points and their assigned cluster centroids.
Because the K-means algorithm depends on distance calculations, it requires numeric data types. The Euclidean distance (or similar measures) can only be computed between numerical values. Therefore, all categorical or text data must first be converted into numeric form through feature engineering techniques such as one-hot encoding, label encoding, or embedding vectors, depending on the nature of the data.
Here’s how K-means works in summary:
The algorithm initializes a predefined number of centroids (K).
Each data point is assigned to the nearest centroid based on numeric distance.
The centroids are recalculated as the mean of the points in each cluster.
The process repeats until convergence.
If non-numeric data (e.g., text or Boolean) were provided, the model would not be able to calculate distances accurately, leading to computational errors.
Other options are incorrect:
Boolean and integer types can represent numeric values but are considered special cases; the algorithm requires general numeric representation (e.g., continuous values).
Text cannot be processed directly without conversion.
Thus, according to Azure Machine Learning and AI-900 official concepts, all features in a K-means clustering model must be numeric to ensure valid mathematical operations and clustering accuracy.

Question # 76
You have a solution that analyzes social media posts to extract the mentions of city names and the city names discussed most frequently.
Which type of natural language processing (NLP) workload does the solution use?
A.
sentiment analysis
B.
key phrase extraction
C.
speech recognition
D.
entity recognition
Full Access
Answer:
D
Question # 77
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

The correct answer is Azure AI Language, which includes the Question Answering capability (previously known as QnA Maker). According to the Microsoft Azure AI Fundamentals (AI-900) study guide and Microsoft Learn documentation, the Azure AI Language service can be used to create a knowledge base from frequently asked questions (FAQ) and other structured or semi-structured text sources.
This service allows developers to build intelligent applications that can understand and respond to user questions in natural language by referencing prebuilt or custom knowledge bases. The Question Answering feature extracts pairs of questions and answers from documents, websites, or manually entered data and uses them to construct a searchable knowledge base. This knowledge base can then be integrated with Azure Bot Service or other conversational platforms to create interactive, self-service chatbots.
Here’s how it works:
Developers upload FAQ documents, URLs, or structured content.
Azure AI Language processes the content and identifies logical question-answer pairs.
The model stores these pairs in a knowledge base that can be queried by user input.
When users ask questions, the model finds the best matching answer using natural language understanding techniques.
In contrast:
Azure AI Document Intelligence (Form Recognizer) is used to extract structured data from forms and documents, not to create FAQ knowledge bases.
Azure AI Bot Service is for managing and deploying conversational bots but does not generate knowledge bases.
Microsoft Bot Framework SDK provides tools for building conversational logic but still requires a knowledge source like Question Answering from Azure AI Language.
Therefore, the service that can create a knowledge base from FAQ content is Azure AI Language.
Question # 78
To complete the sentence, select the appropriate option in the answer area.

Full Access
Answer:
Answer: 
Explanation:
Reliability & Safety
https://en.wikipedia.org/wiki/Tay_(bot)
“To build trust, it ' s critical that AI systems operate reliably, safely, and consistently under normal circumstances and in unexpected conditions. These systems should be able to operate as they were originally designed, respond safely to unanticipated conditions, and resist harmful manipulation. It ' s also important to be able to verify that these systems are behaving as intended under actual operating conditions. How they behave and the variety of conditions they can handle reliably and safely largely reflects the range of situations and circumstances that developers anticipate during design and testing. We believe that rigorous testing is essential during system development and deployment to ensure AI systems can respond safely in unanticipated situations and edge cases, don ' t have unexpected performance failures, and don ' t evolve in ways that are inconsistent with original expectationsâ€
Question # 79
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore fundamental principles of machine learning,†a regression model is used when the goal is to predict a continuous numerical value based on historical data.
In this question, the task is to predict the sale price of auctioned items, which is a numeric output that can take on a wide range of values (for example, $50.25, $199.99, etc.). This makes it a regression problem because the output is continuous rather than categorical.
Regression models analyze the relationship between input features (such as item type, condition, age, bidding history, or demand) and a numerical target variable (the sale price). Common regression algorithms include linear regression, decision tree regression, and neural network regression. In Azure Machine Learning, these models are trained using labeled datasets containing known outcomes to learn patterns and make future predictions.
Let’s review the incorrect options:
Classification: Used to predict discrete categories or labels, such as “sold†vs. “unsold†or “low,†“medium,†“high.†It cannot output continuous numeric predictions.
Clustering: An unsupervised technique used to group similar data points based on shared characteristics, not to predict specific numeric outcomes.
Therefore, because predicting a sale price involves forecasting a continuous numerical value, the correct model type is Regression.
This aligns with Microsoft’s AI-900 teaching that regression is used for tasks such as:
Predicting house prices
Forecasting sales revenue
Estimating car values or auction prices
Question # 80
Match the Al workload to the appropriate task.
To answer, drag the appropriate Al workload from the column on the left to its task on the right. Each workload may be used once, more than once, or not at all
NOTE: Each correct match is worth one point.
Full Access
Answer:
Answer: 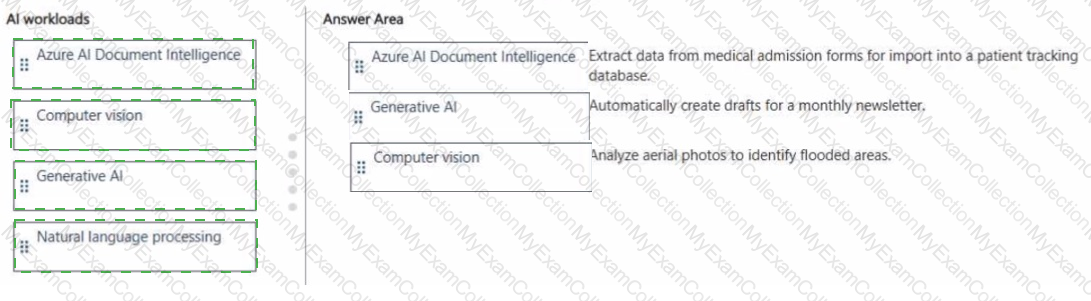
Question # 81
You are developing a model to predict events by using classification.
You have a confusion matrix for the model scored on test data as shown in the following exhibit.
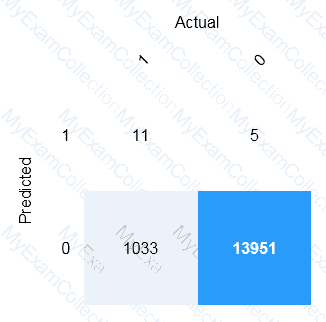
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
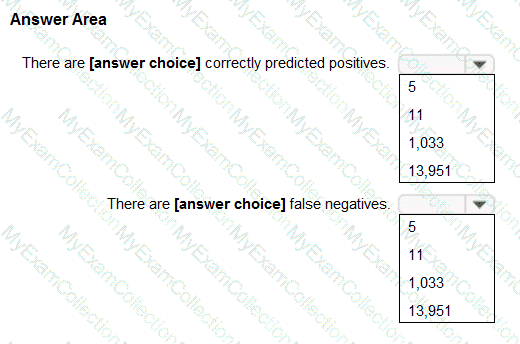
Full Access
Answer:
Answer: 
Explanation:
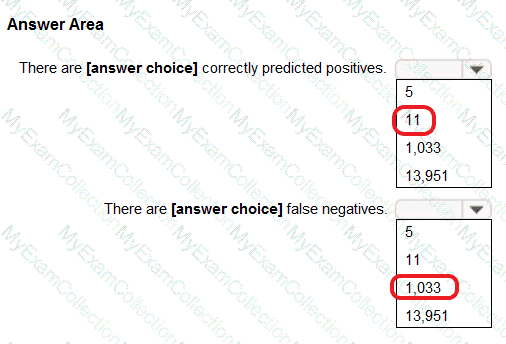
Box 1: 11
TP = True Positive.
The class labels in the training set can take on only two possible values, which we usually refer to as positive or negative. The positive and negative instances that a classifier predicts correctly are called true positives (TP) and true negatives (TN), respectively. Similarly, the incorrectly classified instances are called false positives (FP) and false negatives (FN).
Box 2: 1,033
FN = False Negative
[Reference:, https://docs.microsoft.com/en-us/azure/machine-learning/studio/evaluate-model-performance, , Finding TP is easy. It basically means the value where Predicted and True value is 1 and that is 11 in this case., False Negative means where true value was 1 but predicted value was 0 and that is 1033 in this case, The confusion matrix shows cases where both the predicted and actual values were 1 (known as true positives) at the top left, and cases where both the predicted and the actual values were 0 (true negatives) at the bottom right. The other cells show cases where the predicted and actual values differ (false positives and false negatives)., , https://docs.microsoft.com/en-us/learn/modules/create-classification-model-azure-machine-learning-designer/evaluate-model, , , , ]
Question # 82
You are developing a natural language processing solution in Azure. The solution will analyze customer reviews and determine how positive or negative each review is.
This is an example of which type of natural language processing workload?
A.
language detection
B.
sentiment analysis
C.
key phrase extraction
D.
entity recognition
Full Access
Answer:
B
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore natural language processing (NLP) in Azure,†sentiment analysis is a core natural language processing (NLP) workload used to determine the emotional tone or attitude expressed in a piece of text. It helps identify whether a statement, review, or comment conveys a positive, negative, neutral, or mixed sentiment.
In this question, the scenario involves analyzing customer reviews and determining how positive or negative each review is. This directly aligns with sentiment analysis, which evaluates subjective text and quantifies the expressed opinion. In Azure, this workload is implemented through the Azure AI Language service (formerly Text Analytics API), where the Sentiment Analysis feature assigns a sentiment score to text inputs and classifies them accordingly.
For example:
“I love this product!†→ Positive sentiment
“It’s okay, but could be better.†→ Neutral or mixed sentiment
“I’m disappointed with the service.†→ Negative sentiment
Let’s analyze why the other options are incorrect:
A. Language detection: Identifies which language (e.g., English, Spanish, French) the text is written in. It doesn’t measure positivity or negativity.
C. Key phrase extraction: Identifies the main topics or keywords in text (e.g., “battery life,†“customer supportâ€), not the emotion.
D. Entity recognition: Detects and categorizes specific entities such as people, locations, organizations, or dates within the text.
Therefore, based on Microsoft’s AI-900 syllabus and Azure AI Language documentation, the workload that analyzes text to determine positive or negative opinions is Sentiment Analysis (Option B). This capability is widely used in customer feedback analysis, brand monitoring, and social media analytics to understand public perception and improve business decisions.
Question # 83
You plan to use Azure Machine Learning Studio and automated machine learning (automated ML) to build and train a model What should you create first?
A.
a Jupyter notebook
B.
a Machine Learning workspace
C.
a registered dataset
D.
a Machine Learning designer pipeline
Full Access
Answer:
B
Explanation:
Before building or training any model in Azure Machine Learning Studio—including when using Automated ML (AutoML)—you must first create a Machine Learning workspace.
A workspace serves as the central environment for all machine learning assets such as datasets, compute targets, models, pipelines, and experiments. According to the AI-900 study guide and Microsoft Learn module “Describe features and tools for machine learning in Azure,†a workspace is the foundational setup required to organize and manage all ML-related resources.
The sequence typically follows these steps:
Create a Machine Learning workspace.
Configure compute resources (e.g., compute instance or cluster).
Upload or register datasets.
Use Automated ML or Designer to train models.
Deploy and manage the trained models.
Option A (Jupyter notebook) is an optional tool for coding experiments.
Option C (Registered dataset) is created after the workspace exists.
Option D (Designer pipeline) is a visual tool used within the workspace.
Hence, B. a Machine Learning workspace is the correct answer because it is the first and mandatory step before using Automated ML or any training component in Azure Machine Learning Studio.
Question # 84
What are two tasks that can be performed by using the Computer Vision service? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A.
Train a custom image classification model.
B.
Detect faces in an image.
C.
Recognize handwritten text.
D.
Translate the text in an image between languages.
Full Access
Answer:
B, C
Explanation:
B: Azure ' s Computer Vision service provides developers with access to advanced algorithms that process images and return information based on the visual features you ' re interested in. For example, Computer Vision can determine whether an image contains adult content, find specific brands or objects, or find human faces.
C: Computer Vision includes Optical Character Recognition (OCR) capabilities. You can use the new Read API to extract printed and handwritten text from images and documents.
[Reference:, https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/home, , Detect faces in an image - Face API, Microsoft Azure provides multiple cognitive services that you can use to detect and analyze faces, including:, Computer Vision, which offers face detection and some basic face analysis, such as determining age., Video Indexer, which you can use to detect and identify faces in a video., Face, which offers pre-built algorithms that can detect, recognize, and analyze faces., Recognize hand written text - Read API, The Read API is a better option for scanned documents that have a lot of text. The Read API also has the ability to automatically determine the proper recognition model, , , ]
Question # 85
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify features of common machine learning typesâ€, regression is a supervised machine learning technique used to predict continuous numerical values based on one or more input features. In this scenario, the task is to predict a vehicle’s miles per gallon (MPG)—a continuous numeric value—based on several measurable factors such as weight, engine power, and other specifications.
Regression models learn the mathematical relationship between input variables (independent features) and a numeric target variable (dependent outcome). Common regression algorithms include linear regression, decision tree regression, and support vector regression. In the example, the model would analyze historical data of vehicles and learn patterns that map characteristics (like engine size, horsepower, and weight) to fuel efficiency. Once trained, it can predict the MPG for a new vehicle configuration.
The other options describe different problem types:
Classification predicts discrete categories (for example, whether a car is “fuel efficient†or “not fuel efficientâ€), not continuous values.
Clustering is an unsupervised learning method that groups data points based on similarities without predefined labels, not predictive modeling.
Anomaly detection identifies data points that significantly deviate from normal patterns, such as detecting engine sensor failures or fraudulent transactions.
Since predicting MPG involves estimating a numeric value within a continuous range, regression is the most appropriate model type.
In summary, per AI-900 training content, regression models are used when the output variable is numeric, classification for categorical outputs, and clustering for pattern discovery. Therefore, predicting miles per gallon based on vehicle features is a textbook example of a regression problem in Azure Machine Learning.
Question # 86
Which two tools can you use to call the Azure OpenAI service? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
A.
Azure Command-Line Interface (CLI)
B.
Azure REST API
C.
Azure SDK for Python
D.
Azure SDK for JavaScript
Full Access
Answer:
B, C
Explanation:
The correct answers are B. Azure REST API and C. Azure SDK for Python.
The Azure OpenAI Service can be accessed using multiple development interfaces. According to Microsoft Learn documentation, developers can call the service via the Azure REST API, which provides direct HTTPS-based access to the model endpoints for tasks like completions, chat, embeddings, and image generation. This interface is platform-independent and supports integration with any system capable of making HTTP requests.
Additionally, Azure SDKs offer higher-level libraries for convenient integration into applications. The Azure SDK for Python and Azure SDK for JavaScript are both supported for Azure OpenAI interaction, allowing developers to authenticate with Azure credentials, send prompts, and receive model responses programmatically.
However, among the listed options, the REST API (B) and SDK for Python (C) are most explicitly referenced in the AI-900 learning modules and Microsoft documentation as standard tools to call Azure OpenAI services.
Option A (Azure CLI) is incorrect because the CLI is used primarily for provisioning and managing Azure resources, not for directly calling OpenAI model endpoints.
Therefore, based on the Azure AI-900 and OpenAI integration guidance, the correct answers are B. Azure REST API and C. Azure SDK for Python.
Question # 87
For a machine learning progress, how should you split data for training and evaluation?
A.
Use features for training and labels for evaluation.
B.
Randomly split the data into rows for training and rows for evaluation.
C.
Use labels for training and features for evaluation.
D.
Randomly split the data into columns for training and columns for evaluation.
Full Access
Answer:
B
Explanation:
https://docs.microsoft.com/en-us/azure/machine-learning/algorithm-module-reference/split-data
The correct answer is B. Randomly split the data into rows for training and rows for evaluation.
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Describe fundamental principles of machine learning on Azureâ€, the process of developing a machine learning model involves dividing the available dataset into two or more parts—commonly training data and evaluation (or testing) data. The goal is to ensure that the model can learn patterns from one subset of the data (training set) and then be objectively tested on unseen data (evaluation set) to measure how well it generalizes to new situations.
The training dataset contains both features (the measurable inputs) and labels (the target outputs). The model learns from the patterns and relationships between these features and labels. The evaluation dataset also contains features and labels, but it is kept separate during the training phase. Once the model has been trained, it is tested on this unseen evaluation data to calculate metrics like accuracy, precision, recall, or F1 score.
Microsoft emphasizes that the data split should be random and based on rows, not columns. Each row represents a complete observation (for example, one customer record, one transaction, or one image). Randomly splitting ensures that both subsets represent the same distribution of data, avoiding bias. Splitting by columns would separate features themselves, which would make the model training invalid.
The AI-900 materials often illustrate this using Azure Machine Learning’s data preparation workflow, where data is randomly divided (commonly 70% for training and 30% for testing). This ensures the model learns from diverse examples and is fairly evaluated.
Therefore, the verified and correct approach, as per Microsoft’s official guidance, is B. Randomly split the data into rows for training and rows for evaluation.
Question # 88
What is an example of a Microsoft responsible Al principle?
A.
Al systems should treat people fairly.
B.
Al systems should NOT reveal the details of their design.
C.
Al systems should use black-box models.
D.
Al systems should protect the interests of developers.
Full Access
Answer:
A
Explanation:
Full Detailed Explanation (250–300 words):
The correct answer is A. AI systems should treat people fairly.
This statement aligns with one of Microsoft’s six Responsible AI principles, which are:
Fairness – AI systems should treat all people fairly and avoid bias.
Reliability and Safety
Privacy and Security
Inclusiveness
Transparency
Accountability
The principle of Fairness ensures that AI models do not discriminate based on factors such as race, gender, age, or socioeconomic background. For example, a loan approval or hiring model must provide equal opportunity to all qualified applicants regardless of demographic differences.
B (Not revealing design details) contradicts Transparency, which promotes openness about AI functionality.
C (Black-box models) goes against Microsoft’s push for Explainable AI.
D (Protect developers’ interests) is not part of Microsoft’s Responsible AI framework.
Therefore, the verified correct answer is A. AI systems should treat people fairly.
Question # 89
You have the following apps:
• App1: Understands the public perception of a brand or topic
• App2: Applies profanity filters to speech-to-text
What does each app use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Full Access
Answer:
Answer: 
Explanation:

App1: “Understands the public perception of a brand or topic†→ Sentiment analysis
According to the Microsoft Azure AI Fundamentals (AI-900) study guide and Microsoft Learn’s Natural Language Processing (NLP) documentation, Sentiment analysis is a feature of the Azure AI Language Service that determines the emotional tone or attitude expressed in text. It classifies text as positive, negative, neutral, or mixed, which makes it ideal for analyzing customer opinions, brand perception, or product feedback.
For example, an organization can use sentiment analysis to process customer reviews or social media posts to determine how people feel about a particular brand or topic. This insight helps companies assess customer satisfaction, public perception, and marketing impact.
App2: “Applies profanity filters to speech-to-text†→ Language detection
The task of applying profanity filters occurs during or after speech-to-text transcription, which involves identifying the language used so that the correct filter can be applied. Language detection is an NLP feature that determines which language is being spoken or written. Once the language is detected, appropriate profanity filtering rules are automatically applied to remove or mask offensive words from transcribed text.
Other options such as Captioning or Named Entity Recognition (NER) are not relevant:
Captioning describes images or videos, not speech filtering.
NER identifies people, locations, or organizations but does not handle profanity or language detection.
Therefore, based on Azure AI NLP features:
App1 uses Sentiment analysis
App2 uses Language detection
Question # 90
Select the answer that correctly completes the sentence.

Full Access
Answer:
Answer: 
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore fundamental principles of machine learning,†regression is a type of supervised machine learning used to predict continuous numeric values.
In this question, the goal is to predict how many vehicles will travel across a bridge on a given day. The predicted output (the number of vehicles) is a continuous value—meaning it can take on any numerical value depending on various factors like time, weather, or day of the week. This makes it a regression problem, as the model learns from historical numeric data to estimate a continuous outcome.
How Regression Works:
Regression models find patterns between input features (such as temperature, weekday/weekend, traffic trends) and a numerical output (number of vehicles). Common regression algorithms include linear regression, decision trees for regression, and neural network regression. In Azure Machine Learning, regression tasks are used for business scenarios such as:
Predicting sales revenue for a future month.
Estimating house prices based on property characteristics.
Forecasting energy consumption or traffic flow, as in this case.
Why not the other options?
Classification: Used for predicting discrete categories (e.g., “spam†vs. “not spamâ€). It does not handle continuous numeric values.
Clustering: An unsupervised learning technique used to group data points based on similarity without predefined labels (e.g., segmenting customers into groups).
Therefore, the task of predicting the number of vehicles—a numeric, continuous value—is a regression problem.
Question # 91
Which two languages can you use to write custom code for Azure Machine Learning designer? Each correct answer presents a complete solution.
NOTE; Each correct selection is worth one point.
A.
C#
B.
Scala
C.
Python
D.
R
Full Access
Answer:
C, D
Explanation:
According to the Microsoft Learn module “Describe features of Azure Machine Learning†and the AI-900 study guide, Azure Machine Learning designer supports extending workflows through custom code modules written in Python and R.
Python is the most commonly used language for AI and machine learning due to its extensive library support (such as TensorFlow, Scikit-learn, and PyTorch).
R is widely used for statistical computing and data visualization, making it valuable for analytical workloads.
In Azure Machine Learning, users can insert Python Script or Execute R Script modules within the visual designer to perform advanced operations or custom data transformations.
C# and Scala are not supported directly in Azure Machine Learning Designer. C# is more common in application development, and Scala is primarily used in big data frameworks like Apache Spark.
Hence, the correct answers are C. Python and D. R.
Question # 92
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Full Access
Answer:
Answer: 
Explanation:

 “Generative AI enables software applications to generate new content, such as language dialogs and images.†— YES
This statement is true. According to the Microsoft Azure AI Fundamentals (AI-900) study guide and Microsoft Learn documentation, Generative AI refers to systems capable of creating new content such as text, audio, images, video, and code. Models like GPT, DALL·E, and Codex use deep learning to generate human-like responses, natural conversations, or creative media. This is a key differentiator between generative and discriminative AI — generative AI produces new data, while discriminative AI categorizes or analyzes existing data.
 “The difference between a large language model (LLM) and a small language model (SLM) is the number of variables in the model.†— YES
This statement is true. The primary distinction between an LLM and an SLM lies in the scale of parameters (variables) within the neural network. LLMs contain billions or even trillions of parameters, which enable them to capture complex linguistic patterns and perform broader tasks. SLMs have fewer parameters, making them faster but less capable of handling complex, context-rich tasks.
 “Generative AI is a type of supervised learning.†— NO
This statement is false. Generative AI models are typically trained using unsupervised or self-supervised learning methods. They learn by predicting missing or next elements in large text or image datasets rather than relying on labeled input-output pairs, which are used in supervised learning.
Question # 93
You use Azure Machine Learning designer to publish an inference pipeline.
Which two parameters should you use to consume the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A.
the model name
B.
the training endpoint
C.
the authentication key
D.
the REST endpoint
Full Access
Answer:
C, D
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore Azure Machine Learningâ€, when you publish an inference pipeline (a deployed web service for real-time predictions) using Azure Machine Learning designer, you make the model accessible as a RESTful endpoint. Consumers—such as applications, scripts, or services—interact with this endpoint to submit data and receive predictions.
To securely access this deployed pipeline, two critical parameters are required:
REST endpoint (Option D):The REST endpoint is a URL automatically generated when the inference pipeline is deployed. It defines the network location where clients send HTTP POST requests containing input data (usually in JSON format). The endpoint routes these requests to the deployed model, which processes the data and returns prediction results. The REST endpoint acts as the primary access point for consuming the model’s inferencing capability programmatically.
Authentication key (Option C):The authentication key (or API key) is a security token provided by Azure to ensure that only authorized users or systems can access the endpoint. When invoking the REST service, the key must be included in the request header (typically as the value of the Authorization header). This mechanism enforces secure, authenticated access to the deployed model.
The other options are incorrect:
A. The model name is not required to consume the endpoint; it is used internally within the workspace.
B. The training endpoint is used for training pipelines, not for inference.
Therefore, according to Microsoft’s official AI-900 learning objectives and Azure Machine Learning documentation, when consuming a published inference pipeline, you must use both the REST endpoint (D) and the authentication key (C). These parameters ensure secure, controlled, and programmatic access to the deployed AI model for real-time predictions.
Question # 94
You need to track multiple versions of a model that was trained by using Azure Machine Learning. What should you do?
A.
Provision an inference duster.
B.
Explain the model.
C.
Register the model.
D.
Register the training data.
Full Access
Answer:
C
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore Azure Machine Learning,†registering a model is the correct way to track multiple versions of models in Azure Machine Learning.
When you train models in Azure Machine Learning, each trained version can be registered in the workspace’s Model Registry. Registration stores the model’s metadata, including version, training environment, parameters, and lineage. Each registration automatically increments the version number, enabling you to manage, deploy, and compare multiple model iterations efficiently.
The other options are incorrect:
A. Provision an inference cluster – Used for model deployment, not version tracking.
B. Explain the model – Provides interpretability but does not track versions.
D. Register the training data – Registers data assets, not models.
Question # 95
An app that analyzes social media posts to identify their tone is an example of which type of natural language processing (NLP) workload?
A.
sentiment analysis
B.
key phrase extraction
C.
entity recognition
D.
speech recognition
Full Access
Answer:
A
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Describe features of natural language processing (NLP) workloads on Azure,†sentiment analysis is an NLP workload that determines the emotional tone or opinion expressed in a piece of text. This could be positive, negative, or neutral sentiment.
When an app analyzes social media posts to identify their tone, it is performing sentiment analysis, since it aims to understand the emotional context behind user-generated text such as tweets, reviews, or comments. Azure provides this functionality through the Azure Cognitive Services – Text Analytics API, which evaluates text and returns sentiment scores.
Other options are not suitable:
Key phrase extraction identifies main ideas in text but not tone.
Entity recognition identifies names of people, organizations, or locations.
Speech recognition converts spoken words into text, not emotional analysis.
Therefore, analyzing social media tone is an example of sentiment analysis, a key NLP workload in Microsoft’s AI-900 syllabus.
Question # 96
During the process of Machine Learning, when should you review evaluation metrics?
A.
After you clean the data.
B.
Before you train a model.
C.
Before you choose the type of model.
D.
After you test a model on the validation data.
Full Access
Answer:
D
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials and the Microsoft Learn module “Identify features of common machine learning types,†the evaluation phase occurs after training and testing a machine learning model. Evaluation metrics are used to measure how well the model performs when applied to data it has not seen before (the validation data).
The machine learning workflow includes the following key steps:
Data Preparation – Importing, cleaning, and transforming data.
Splitting the Data – Dividing it into training and validation (or test) sets.
Model Training – Using the training data to teach the model patterns or relationships.
Model Evaluation – Assessing the trained model using the validation data and evaluation metrics such as accuracy, precision, recall, F1 score, and root mean square error (RMSE).
As stated in the AI-900 content, evaluation metrics are crucial after testing, as they help determine if the model is accurate enough or if it requires retraining with different parameters or algorithms.
A. After you clean the data → incorrect, as metrics cannot be reviewed before training.
B. Before you train a model → incorrect, since the model has not yet learned patterns.
C. Before you choose the type of model → incorrect, as metrics depend on the model’s output.
Therefore, the verified answer is D. After you test a model on the validation data, which is when you review evaluation metrics to determine model performance and readiness for deployment.
Question # 97
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE Each correct selection is worth one point

Full Access
Answer:
Answer: 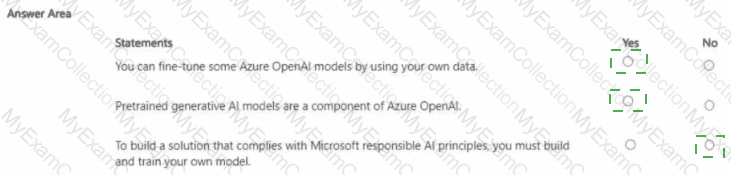
Explanation:
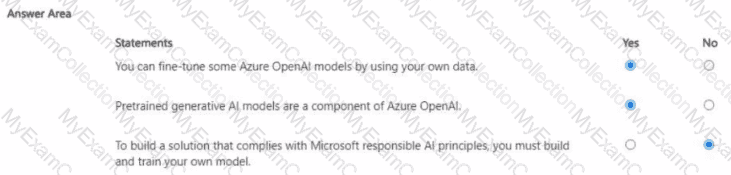
Full Detailed Explanation (250–300 words):
“You can fine-tune some Azure OpenAI models by using your own data.†– YESThis statement is true. Azure OpenAI allows customers to fine-tune certain models like GPT-3, GPT-3.5, and some embedding models with their own data. Fine-tuning customizes a model to perform better on specific tasks or match a company’s domain terminology, tone, or context. According to Microsoft Learn’s AI-900 and Azure OpenAI documentation, fine-tuning is supported for approved use cases while maintaining Microsoft’s Responsible AI oversight and compliance process.
“Pretrained generative AI models are a component of Azure OpenAI.†– YESThis statement is also true. Azure OpenAI provides access to pretrained large language and generative AI models such as GPT-3.5, GPT-4, Codex, and DALL·E. These models are pretrained on vast datasets and made available via APIs, allowing developers to generate text, code, and images without needing to train their own models. This is a core feature of Azure OpenAI’s service offering.
“To build a solution that complies with Microsoft responsible AI principles, you must build and train your own model.†– NOThis statement is false. Compliance with Microsoft Responsible AI principles (Fairness, Reliability & Safety, Privacy & Security, Inclusiveness, Transparency, Accountability) does not require building custom models. Prebuilt Azure AI and OpenAI services already align with Responsible AI standards. Developers simply need to use these services responsibly, applying governance and ethical design practices.
Question # 98
Which type of machine learning should you use to predict the number of gift cards that will be sold next month?
A.
classification
B.
regression
C.
clustering
Full Access
Answer:
B
Explanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify features of regression machine learningâ€, regression is the machine learning technique used when the goal is to predict a continuous numeric value based on historical data. In this question, predicting the number of gift cards that will be sold next month involves forecasting a quantity—a numeric outcome—which is the hallmark of a regression problem.
Regression models learn patterns from past data (for example, previous months’ gift card sales, seasonality, holidays, and marketing spend) and use that information to predict future sales. Common algorithms used for regression include linear regression, decision tree regression, and boosted regression trees. The output is a continuous value such as “2,450 gift cards expected next month.â€
In contrast:
A. Classification is used when the output is categorical, such as predicting whether a transaction is “fraud†or “not fraud,†or whether a customer will “renew†or “cancel.†It answers questions with discrete classes rather than numeric values.
C. Clustering is an unsupervised learning technique used to group similar data points together based on their characteristics—for example, segmenting customers into behavior-based clusters. Clustering doesn’t predict future numeric outcomes.
The AI-900 curriculum explicitly explains that regression predicts numeric values, classification predicts categories, and clustering finds natural groupings in data.
Therefore, to predict the number of gift cards to be sold, the correct and verified machine learning type is Regression.
Final Answer: B. Regression
[Reference:Microsoft Learn – Identify the types of machine learning models: Regression, Classification, and Clustering (AI-900 Learning Path), , , , ]
Question # 99
Which parameter should you configure to produce more verbose responses from a chat solution that uses the Azure OpenAI GPT-3.5 model?
A.
Presence penalty
B.
Temperature
C.
Stop sequence
D.
Max responseB
Full Access
Answer:
B
Explanation:
In a chat solution using the Azure OpenAI GPT-3.5 model, the temperature parameter controls the creativity and variability of generated responses. According to the Microsoft Learn documentation for Azure OpenAI Service, temperature is a float value typically between 0 and 2, determining how deterministic or random the model’s output is. A lower temperature (e.g., 0–0.3) makes responses more focused and deterministic, while a higher temperature (e.g., 0.8–1.2) produces more verbose, creative, and diverse responses.
When you want the chat model to generate more detailed or expressive output, increasing the temperature encourages the model to explore a broader range of possible continuations, leading to longer and more varied text. This parameter directly affects how “verbose†or elaborate the model’s responses can be, which is why it is the correct answer.
The other options are not appropriate for this scenario:
A. Presence penalty reduces repetition by discouraging reuse of the same phrases but does not control verbosity.
C. Stop sequence defines tokens where generation should stop, limiting rather than extending response length.
D. Max response (max tokens) controls the maximum length of the response but does not inherently make answers more verbose or expressive.
Thus, to encourage more elaborate and detailed output from the Azure OpenAI GPT-3.5 model, the correct configuration parameter to adjust is Temperature (B).

