Question # 4
You are asked to design a case management system for a client. In addition to storing some basic metadata about a case, one of the client’s requirements is the ability for users to update a case. The client would like any user in their organization of 500 people to be able to make these updates. The users are all based in the company's headquarters, and there will be frequent cases where users are attempting to edit the same case. The client wants to ensure no information is lost when these edits occur and does not want the solution to burden their process administrators with any additional effort. Which data locking approach should you recommend?
A.
Allow edits without locking the case CDI.
B.
Use the database to implement low-level pessimistic locking.
C.
Add an @Version annotation to the case CDT to manage the locking.
D.
Design a process report and query to determine who opened the edit form first.
Full Access
Answer:
C
Explanation:
Comprehensive and Detailed In-Depth Explanation:
The requirement involves a case management system where 500 users may simultaneously edit the same case, with a need to prevent data loss and minimize administrative overhead. Appian’s data management and concurrency control strategies are critical here, especially when integrating with an underlying database.
Option C (Add an @Version annotation to the case CDT to manage the locking):This is the recommended approach. In Appian, the @Version annotation on a Custom Data Type (CDT) enables optimistic locking, a lightweight concurrency control mechanism. When a user updates a case, Appian checks the version number of the CDT instance. If another user has modified it in the meantime, the update fails, prompting the user to refresh and reapply changes. This prevents data loss without requiring manual intervention by process administrators. Appian’s Data Design Guide recommends @Version for scenarios with high concurrency (e.g., 500 users) and frequent edits, as it leverages the database’s native versioning (e.g., in MySQL or PostgreSQL) and integrates seamlessly with Appian’s process models. This aligns with the client’s no-burden requirement.
Option A (Allow edits without locking the case CDI):This is risky. Without locking, simultaneous edits could overwrite each other, leading to data loss—a direct violation of the client’s requirement. Appian does not recommend this for collaborative environments.
Option B (Use the database to implement low-level pessimistic locking):Pessimistic locking (e.g., using SELECT ... FOR UPDATE in MySQL) locks the record during the edit process, preventing other users from modifying it until the lock is released. While effective, it can lead to deadlocks or performance bottlenecks with 500 users, especially if edits are frequent. Additionally, managing this at the database level requires custom SQL and increases administrative effort (e.g., monitoring locks), which the client wants to avoid. Appian prefers higher-level solutions like @Version over low-level database locking.
Option D (Design a process report and query to determine who opened the edit form first):This is impractical and inefficient. Building a custom report and query to track form opens adds complexity and administrative overhead. It doesn’t inherently prevent data loss and relies on manual resolution, conflicting with the client’s requirements.
The @Version annotation provides a robust, Appian-native solution that balances concurrency, data integrity, and ease of maintenance, making it the best fit.
[References: Appian Documentation - Data Types and Concurrency Control, Appian Data Design Guide - Optimistic Locking with @Version, Appian Lead Developer Training - Case Management Design., , ]
Question # 5
You are developing a case management application to manage support cases for a large set of sites. One of the tabs in this application s site Is a record grid of cases, along with Information about the site corresponding to that case. Users must be able to filter cases by priority level and status.
You decide to create a view as the source of your entity-backed record, which joins the separate case/site tables (as depicted in the following Image).

Which three column should be indexed?
A.
site_id
B.
status
C.
name
D.
modified_date
E.
priority
F.
case_id
Full Access
Answer:
A, B, E
Explanation:
Indexing columns can improve the performance of queries that use those columns in filters, joins, or order by clauses. In this case, the columns that should be indexed are site_id, status, and priority, because they are used for filtering or joining the tables. Site_id is used to join the case and site tables, so indexing it will speed up the join operation. Status and priority are used to filter the cases by the user’s input, so indexing them will reduce the number of rows that need to be scanned. Name, modified_date, and case_id do not need to be indexed, because they are not used for filtering or joining. Name and modified_date are only used for displaying information in the record grid, and case_id is only used as a unique identifier for each record. Verified References: Appian Records Tutorial, Appian Best Practices
As an Appian Lead Developer, optimizing a database view for an entity-backed record grid requires indexing columns frequently used in queries, particularly for filtering and joining. The scenario involves a record grid displaying cases with site information, filtered by “priority level†and “status,†and joined via the site_id foreign key. The image shows two tables (site and case) with a relationship via site_id. Let’s evaluate each column based on Appian’s performance best practices and query patterns:
A. site_id:This is a primary key in the site table and a foreign key in the case table, used for joining the tables in the view. Indexing site_id in the case table (and ensuring it’s indexed in site as a PK) optimizes JOIN operations, reducing query execution time for the record grid. Appian’s documentation recommends indexing foreign keys in large datasets to improve query performance, especially for entity-backed records. This is critical for the join and must be included.
B. status:Users filter cases by “status†(a varchar column in the case table). Indexing status speeds up filtering queries (e.g., WHERE status = 'Open') in the record grid, particularly with large datasets. Appian emphasizes indexing columns used in WHERE clauses or filters to enhance performance, making this a key column for optimization. Since status is a common filter, it’s essential.
C. name:This is a varchar column in the site table, likely used for display (e.g., site name in the grid). However, the scenario doesn’t mention filtering or sorting by name, and it’s not part of the join or required filters. Indexing name could improve searches if used, but it’s not a priority given the focus on priority and status filters. Appian advises indexing only frequently queried or filtered columns to avoid unnecessary overhead, so this isn’t necessary here.
D. modified_date:This is a date column in the case table, tracking when cases were last updated. While useful for sorting or historical queries, the scenario doesn’t specify filtering or sorting by modified_date in the record grid. Indexing it could help if used, but it’s not critical for the current requirements. Appian’s performance guidelines prioritize indexing columns in active filters, making this lower priority than site_id, status, and priority.
E. priority:Users filter cases by “priority level†(a varchar column in the case table). Indexing priority optimizes filtering queries (e.g., WHERE priority = 'High') in the record grid, similar to status. Appian’s documentation highlights indexing columns used in WHERE clauses for entity-backed records, especially with large datasets. Since priority is a specified filter, it’s essential to include.
F. case_id:This is the primary key in the case table, already indexed by default (as PKs are automatically indexed in most databases). Indexing it again is redundant and unnecessary, as Appian’s Data Store configuration relies on PKs for unique identification but doesn’t require additional indexing for performance in this context. The focus is on join and filter columns, not the PK itself.
Conclusion: The three columns to index are A (site_id), B (status), and E (priority). These optimize the JOIN (site_id) and filter performance (status, priority) for the record grid, aligning with Appian’s recommendations for entity-backed records and large datasets. Indexing these columns ensures efficient querying for user filters, critical for the application’s performance.
[References: , Appian Documentation: "Performance Best Practices for Data Stores" (Indexing Strategies). , Appian Lead Developer Certification: Data Management Module (Optimizing Entity-Backed Records). , Appian Best Practices: "Working with Large Data Volumes" (Indexing for Query Performance)., , ]
Question # 6
You are reviewing the Engine Performance Logs in Production for a single application that has been live for six months. This application experiences concurrent user activity and has a fairly sustained load during business hours. The client has reported performance issues with the application during business hours.
During your investigation, you notice a high Work Queue - Java Work Queue Size value in the logs. You also notice unattended process activities, including timer events and sending notification emails, are taking far longer to execute than normal.
The client increased the number of CPU cores prior to the application going live.
What is the next recommendation?
A.
Add more engine replicas.
B.
Optimize slow-performing user interfaces.
C.
Add more application servers.
D.
Add execution and analytics shards
Full Access
Answer:
A
Explanation:
As an Appian Lead Developer, analyzing Engine Performance Logs to address performance issues in a Production application requires understanding Appian’s architecture and the specific metrics described. The scenario indicates a high “Work Queue - Java Work Queue Size,†which reflects a backlog of tasks in the Java Work Queue (managed by Appian engines), and delays in unattended process activities (e.g., timer events, email notifications). These symptoms suggest the Appian engines are overloaded, despite the client increasing CPU cores. Let’s evaluate each option:
A. Add more engine replicas:This is the correct recommendation. In Appian, engine replicas (part of the Appian Engine cluster) handle process execution, including unattended tasks like timers and notifications. A high Java Work Queue Size indicates the engines are overwhelmed by concurrent activity during business hours, causing delays. Adding more engine replicas distributes the workload, reducing queue size and improving performance for both user-driven and unattended tasks. Appian’s documentation recommends scaling engine replicas to handle sustained loads, especially in Production with high concurrency. Since CPU cores were already increased (likely on application servers), the bottleneck is likely the engine capacity, not the servers.
B. Optimize slow-performing user interfaces:While optimizing user interfaces (e.g., SAIL forms, reports) can improve user experience, the scenario highlights delays in unattended activities (timers, emails), not UI performance. The Java Work Queue Size issue points to engine-level processing, not UI rendering, so this doesn’t address the root cause. Appian’s performance tuning guidelines prioritize engine scaling for queue-related issues, making this a secondary concern.
C. Add more application servers:Application servers handle web traffic (e.g., SAIL interfaces, API calls), not process execution or unattended tasks managed by engines. Increasing application servers would help with UI concurrency but wouldn’t reduce the Java Work Queue Size or speed up timer/email processing, as these are engine responsibilities. Since the client already increased CPU cores (likely on application servers), this is redundant and unrelated to the issue.
D. Add execution and analytics shards:Execution shards (for process data) and analytics shards (for reporting) are part of Appian’s data fabric for scalability, but they don’t directly address engine workload or Java Work Queue Size. Shards optimize data storage and query performance, not real-time process execution. The logs indicate an engine bottleneck, not a data storage issue, so this isn’t relevant. Appian’s documentation confirms shards are for long-term scaling, not immediate performance fixes.
Conclusion: Adding more engine replicas (A) is the next recommendation. It directly resolves the high Java Work Queue Size and delays in unattended tasks, aligning with Appian’s architecture for handling concurrent loads in Production. This requires collaboration with system administrators to configure additional replicas in the Appian cluster.
[References: , Appian Documentation: "Engine Performance Monitoring" (Java Work Queue and Scaling Replicas). , Appian Lead Developer Certification: Performance Optimization Module (Engine Scaling Strategies). , Appian Best Practices: "Managing Production Performance" (Work Queue Analysis)., , , ]
Question # 7
What are two advantages of having High Availability (HA) for Appian Cloud applications?
A.
An Appian Cloud HA instance is composed of multiple active nodes running in different availability zones in different regions.
B.
Data and transactions are continuously replicated across the active nodes to achieve redundancy and avoid single points of failure.
C.
A typical Appian Cloud HA instance is composed of two active nodes.
D.
In the event of a system failure, your Appian instance will be restored and available to your users in less than 15 minutes, having lost no more than the last 1 minute worth of data.
Full Access
Answer:
B, D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
High Availability (HA) in Appian Cloud is designed to ensure that applications remain operational and data integrity is maintained even in the face of hardware failures, network issues, or other disruptions. Appian’s Cloud Architecture and HA documentation outline the benefits, focusing on redundancy, minimal downtime, and data protection. The question asks for two advantages, and the options must align with these core principles.
Option B (Data and transactions are continuously replicated across the active nodes to achieve redundancy and avoid single points of failure):This is a key advantage of HA. Appian Cloud HA instances use multiple active nodes to replicate data and transactions in real-time across the cluster. This redundancy ensures that if one node fails, others can take over without data loss, eliminating single points of failure. This is a fundamental feature of Appian’s HA setup, leveraging distributed architecture to enhance reliability, as detailed in the Appian Cloud High Availability Guide.
Option D (In the event of a system failure, your Appian instance will be restored and available to your users in less than 15 minutes, having lost no more than the last 1 minute worth of data):This is another significant advantage. Appian Cloud HA is engineered to provide rapid recovery and minimal data loss. The Service Level Agreement (SLA) and HA documentation specify that in the case of a failure, the system failover is designed to complete within a short timeframe (typically under 15 minutes), with data loss limited to the last minute due to synchronous replication. This ensures business continuity and meets stringent uptime and data integrity requirements.
Option A (An Appian Cloud HA instance is composed of multiple active nodes running in different availability zones in different regions):This is a description of the HA architecture rather than an advantage. While running nodes across different availability zones and regions enhances fault tolerance, the benefit is the resulting redundancy and availability, which are captured in Options B and D. This option is more about implementation than a direct user or operational advantage.
Option C (A typical Appian Cloud HA instance is composed of two active nodes):This is a factual statement about the architecture but not an advantage. The number of nodes (typically two or more, depending on configuration) is a design detail, not a benefit. The advantage lies in what this setup enables (e.g., redundancy and quick recovery), as covered by B and D.
The two advantages—continuous replication for redundancy (B) and fast recovery with minimal data loss (D)—reflect the primary value propositions of Appian Cloud HA, ensuring both operational resilience and data integrity for users.
[References: Appian Documentation - Appian Cloud High Availability Guide, Appian Cloud Service Level Agreement (SLA), Appian Lead Developer Training - Cloud Architecture., , The two advantages of having High Availability (HA) for Appian Cloud applications are:, B. Data and transactions are continuously replicated across the active nodes to achieve redundancy and avoid single points of failure. This is an advantage of having HA, as it ensures that there is always a backup copy of data and transactions in case one of the nodes fails or becomes unavailable. This also improves data integrity and consistency across the nodes, as any changes made to one node are automatically propagated to the other node., D. In the event of a system failure, your Appian instance will be restored and available to your users in less than 15 minutes, having lost no more than the last 1 minute worth of data. This is an advantage of having HA, as it guarantees a high level of service availability and reliability for your Appian instance. If one of the nodes fails or becomes unavailable, the other node will take over and continue to serve requests without any noticeable downtime or data loss for your users., The other options are incorrect for the following reasons:, A. An Appian Cloud HA instance is composed of multiple active nodes running in different availability zones in different regions. This is not an advantage of having HA, but rather a description of how HA works in Appian Cloud. An Appian Cloud HA instance consists of two active nodes running in different availability zones within the same region, not different regions., C. A typical Appian Cloud HA instance is composed of two active nodes. This is not an advantage of having HA, but rather a description of how HA works in Appian Cloud. A typical Appian Cloud HA instance consists of two active nodes running in different availability zones within the same region, but this does not necessarily provide any benefit over having one active node. Verified References: Appian Documentation, section “High Availabilityâ€., , , ]
Question # 8
You need to generate a PDF document with specific formatting. Which approach would you recommend?
A.
Create an embedded interface with the necessary content and ask the user to use the browser "Print" functionality to save it as a PDF.
B.
Use the PDF from XSL-FO Transformation smart service to generate the content with the specific format.
C.
Use the Word Doc from Template smart service in a process model to add the specific format.
D.
There is no way to fulfill the requirement using Appian. Suggest sending the content as a plain email instead.
Full Access
Answer:
B
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, generating a PDF with specific formatting is a common requirement, and Appian provides several tools to achieve this. The question emphasizes "specific formatting," which implies precise control over layout, styling, and content structure. Let’s evaluate each option based on Appian’s official documentation and capabilities:
A. Create an embedded interface with the necessary content and ask the user to use the browser "Print" functionality to save it as a PDF:This approach involves designing an interface (e.g., using SAIL components) and relying on the browser’s native print-to-PDF feature. While this is feasible for simple content, it lacks precision for "specific formatting." Browser rendering varies across devices and browsers, and print styles (e.g., CSS) are limited in Appian’s control. Appian Lead Developer best practices discourage relying on client-side functionality for critical document generation due to inconsistency and lack of automation. This is not a recommended solution for a production-grade requirement.
B. Use the PDF from XSL-FO Transformation smart service to generate the content with the specific format:This is the correct choice. The "PDF from XSL-FO Transformation" smart service (available in Appian’s process modeling toolkit) allows developers to generate PDFs programmatically with precise formatting using XSL-FO (Extensible Stylesheet Language Formatting Objects). XSL-FO provides fine-grained control over layout, fonts, margins, and styling—ideal for "specific formatting" requirements. In a process model, you can pass XML data and an XSL-FO stylesheet to this smart service, producing a downloadable PDF. Appian’s documentation highlights this as the preferred method for complex PDF generation, making it a robust, scalable, and Appian-native solution.
C. Use the Word Doc from Template smart service in a process model to add the specific format:This option uses the "Word Doc from Template" smart service to generate a Microsoft Word document from a template (e.g., a .docx file with placeholders). While it supports formatting defined in the template and can be converted to PDF post-generation (e.g., via a manual step or external tool), it’s not a direct PDF solution. Appian doesn’t natively convert Word to PDF within the platform, requiring additional steps outside the process model. For "specific formatting" in a PDF, this is less efficient and less precise than the XSL-FO approach, as Word templates are better suited for editable documents rather than final PDFs.
D. There is no way to fulfill the requirement using Appian. Suggest sending the content as a plain email instead:This is incorrect. Appian provides multiple tools for document generation, including PDFs, as evidenced by options B and C. Suggesting a plain email fails to meet the requirement of generating a formatted PDF and contradicts Appian’s capabilities. Appian Lead Developer training emphasizes leveraging platform features to meet business needs, ruling out this option entirely.
Conclusion: The PDF from XSL-FO Transformation smart service (B) is the recommended approach. It provides direct PDF generation with specific formatting control within Appian’s process model, aligning with best practices for document automation and precision. This method is scalable, repeatable, and fully supported by Appian’s architecture.
[References: , Appian Documentation: "PDF from XSL-FO Transformation Smart Service" (Process Modeling > Smart Services). , Appian Lead Developer Certification: Document Generation Module (PDF Generation Techniques). , Appian Best Practices: "Generating Documents in Appian" (XSL-FO vs. Template-Based Approaches)., , , ]
Question # 9
You need to design a complex Appian integration to call a RESTful API. The RESTful API will be used to update a case in a customer’s legacy system.
What are three prerequisites for designing the integration?
A.
Define the HTTP method that the integration will use.
B.
Understand the content of the expected body, including each field type and their limits.
C.
Understand whether this integration will be used in an interface or in a process model.
D.
Understand the different error codes managed by the API and the process of error handling in Appian.
E.
Understand the business rules to be applied to ensure the business logic of the data.
Full Access
Answer:
A, B, D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a complex integration to a RESTful API for updating a case in a legacy system requires a structured approach to ensure reliability, performance, and alignment with business needs. The integration involves sending a JSON payload (implied by the context) and handling responses, so the focus is on technical and functional prerequisites. Let’s evaluate each option:
A. Define the HTTP method that the integration will use:This is a primary prerequisite. RESTful APIs use HTTP methods (e.g., POST, PUT, GET) to define the operation—here, updating a case likely requires PUT or POST. Appian’s Connected System and Integration objects require specifying the method to configure the HTTP request correctly. Understanding the API’s method ensures the integration aligns with its design, making this essential for design. Appian’s documentation emphasizes choosing the correct HTTP method as a foundational step.
B. Understand the content of the expected body, including each field type and their limits:This is also critical. The JSON payload for updating a case includes fields (e.g., text, dates, numbers), and the API expects a specific structure with field types (e.g., string, integer) and limits (e.g., max length, size constraints). In Appian, the Integration object requires a dictionary or CDT to construct the body, and mismatches (e.g., wrong types, exceeding limits) cause errors (e.g., 400 Bad Request). Appian’s best practices mandate understanding the API schema to ensure data compatibility, making this a key prerequisite.
C. Understand whether this integration will be used in an interface or in a process model:While knowing the context (interface vs. process model) is useful for design (e.g., synchronous vs. asynchronous calls), it’s not a prerequisite for the integration itself—it’s a usage consideration. Appian supports integrations in both contexts, and the integration’s design (e.g., HTTP method, body) remains the same. This is secondary to technical API details, so it’s not among the top three prerequisites.
D. Understand the different error codes managed by the API and the process of error handling in Appian:This is essential. RESTful APIs return HTTP status codes (e.g., 200 OK, 400 Bad Request, 500 Internal Server Error), and the customer’s API likely documents these for failure scenarios (e.g., invalid data, server issues). Appian’s Integration objects can handle errors via error mappings or process models, and understanding these codes ensures robust error handling (e.g., retry logic, user notifications). Appian’s documentation stresses error handling as a core design element for reliable integrations, making this a primary prerequisite.
E. Understand the business rules to be applied to ensure the business logic of the data:While business rules (e.g., validating case data before sending) are important for the overall application, they aren’t a prerequisite for designing the integration itself—they’re part of the application logic (e.g., process model or interface). The integration focuses on technical interaction with the API, not business validation, which can be handled separately in Appian. This is a secondary concern, not a core design requirement for the integration.
Conclusion: The three prerequisites are A (define the HTTP method), B (understand the body content and limits), and D (understand error codes and handling). These ensure the integration is technically sound, compatible with the API, and resilient to errors—critical for a complex RESTful API integration in Appian.
[References: , Appian Documentation: "Designing REST Integrations" (HTTP Methods, Request Body, Error Handling). , Appian Lead Developer Certification: Integration Module (Prerequisites for Complex Integrations). , Appian Best Practices: "Building Reliable API Integrations" (Payload and Error Management)., , To design a complex Appian integration to call a RESTful API, you need to have some prerequisites, such as:, Define the HTTP method that the integration will use. The HTTP method is the action that the integration will perform on the API, such as GET, POST, PUT, PATCH, or DELETE. The HTTP method determines how the data will be sent and received by the API, and what kind of response will be expected., Understand the content of the expected body, including each field type and their limits. The body is the data that the integration will send to the API, or receive from the API, depending on the HTTP method. The body can be in different formats, such as JSON, XML, or form data. You need to understand how to structure the body according to the API specification, and what kind of data types and values are allowed for each field., Understand the different error codes managed by the API and the process of error handling in Appian. The error codes are the status codes that indicate whether the API request was successful or not, and what kind of problem occurred if not. The error codes can range from 200 (OK) to 500 (Internal Server Error), and each code has a different meaning and implication. You need to understand how to handle different error codes in Appian, and how to display meaningful messages to the user or log them for debugging purposes., The other two options are not prerequisites for designing the integration, but rather considerations for implementing it., Understand whether this integration will be used in an interface or in a process model. This is not a prerequisite, but rather a decision that you need to make based on your application requirements and design. You can use an integration either in an interface or in a process model, depending on where you need to call the API and how you want to handle the response. For example, if you need to update a case in real-time based on user input, you may want to use an integration in an interface. If you need to update a case periodically based on a schedule or an event, you may want to use an integration in a process model., Understand the business rules to be applied to ensure the business logic of the data. This is not a prerequisite, but rather a part of your application logic that you need to implement after designing the integration. You need to apply business rules to validate, transform, or enrich the data that you send or receive from the API, according to your business requirements and logic. For example, you may need to check if the case status is valid before updating it in the legacy system, or you may need to add some additional information to the case data before displaying it in Appian., , ]
Question # 10
As part of your implementation workflow, users need to retrieve data stored in a third-party Oracle database on an interface. You need to design a way to query this information.
How should you set up this connection and query the data?
A.
Configure a Query Database node within the process model. Then, type in the connection information, as well as a SQL query to execute and return the data in process variables.
B.
Configure a timed utility process that queries data from the third-party database daily, and stores it in the Appian business database. Then use a!queryEntity using the Appian data source to retrieve the data.
C.
Configure an expression-backed record type, calling an API to retrieve the data from the third-party database. Then, use a!queryRecordType to retrieve the data.
D.
In the Administration Console, configure the third-party database as a “New Data Source.†Then, use a!queryEntity to retrieve the data.
Full Access
Answer:
D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a solution to query data from a third-party Oracle database for display on an interface requires secure, efficient, and maintainable integration. The scenario focuses on real-time retrieval for users, so the design must leverage Appian’s data connectivity features. Let’s evaluate each option:
A. Configure a Query Database node within the process model. Then, type in the connection information, as well as a SQL query to execute and return the data in process variables:The Query Database node (part of the Smart Services) allows direct SQL execution against a database, but it requires manual connection details (e.g., JDBC URL, credentials), which isn’t scalable or secure for Production. Appian’s documentation discourages using Query Database for ongoing integrations due to maintenance overhead, security risks (e.g., hardcoding credentials), and lack of governance. This is better for one-off tasks, not real-time interface queries, making it unsuitable.
B. Configure a timed utility process that queries data from the third-party database daily, and stores it in the Appian business database. Then use a!queryEntity using the Appian data source to retrieve the data:This approach syncs data daily into Appian’s business database (e.g., via a timer event and Query Database node), then queries it with a!queryEntity. While it works for stale data, it introduces latency (up to 24 hours) for users, which doesn’t meet real-time needs on an interface. Appian’s best practices recommend direct data source connections for up-to-date data, not periodic caching, unless latency is acceptable—making this inefficient here.
C. Configure an expression-backed record type, calling an API to retrieve the data from the third-party database. Then, use a!queryRecordType to retrieve the data:Expression-backed record types use expressions (e.g., a!httpQuery()) to fetch data, but they’re designed for external APIs, not direct database queries. The scenario specifies an Oracle database, not an API, so this requires building a custom REST service on the Oracle side, adding complexity and latency. Appian’s documentation favors Data Sources for database queries over API calls when direct access is available, making this less optimal and over-engineered.
D. In the Administration Console, configure the third-party database as a “New Data Source.†Then, use a!queryEntity to retrieve the data:This is the best choice. In the Appian Administration Console, you can configure a JDBC Data Source for the Oracle database, providing connection details (e.g., URL, driver, credentials). This creates a secure, managed connection for querying via a!queryEntity, which is Appian’s standard function for Data Store Entities. Users can then retrieve data on interfaces using expression-backed records or queries, ensuring real-time access with minimal latency. Appian’s documentation recommends Data Sources for database integrations, offering scalability, security, and governance—perfect for this requirement.
Conclusion: Configuring the third-party database as a New Data Source and using a!queryEntity (D) is the recommended approach. It provides direct, real-time access to Oracle data for interface display, leveraging Appian’s native data connectivity features and aligning with Lead Developer best practices for third-party database integration.
[References: , Appian Documentation: "Configuring Data Sources" (JDBC Connections and a!queryEntity). , Appian Lead Developer Certification: Data Integration Module (Database Query Design). , Appian Best Practices: "Retrieving External Data in Interfaces" (Data Source vs. API Approaches)., , ]
Question # 11
You are required to create an integration from your Appian Cloud instance to an application hosted within a customer’s self-managed environment.
The customer’s IT team has provided you with a REST API endpoint to test with: https://internal.network/api/api/ping.
Which recommendation should you make to progress this integration?
A.
Expose the API as a SOAP-based web service.
B.
Deploy the API/service into Appian Cloud.
C.
Add Appian Cloud’s IP address ranges to the customer network’s allowed IP listing.
D.
Set up a VPN tunnel.
Full Access
Answer:
D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, integrating an Appian Cloud instance with a customer’s self-managed (on-premises) environment requires addressing network connectivity, security, and Appian’s cloud architecture constraints. The provided endpoint (https://internal.network/api/api/ping) is a REST API on an internal network, inaccessible directly from Appian Cloud due to firewall restrictions and lack of public exposure. Let’s evaluate each option:
A. Expose the API as a SOAP-based web service:Converting the REST API to SOAP isn’t a practical recommendation. The customer has provided a REST endpoint, and Appian fully supports REST integrations via Connected Systems and Integration objects. Changing the API to SOAP adds unnecessary complexity, development effort, and risks for the customer, with no benefit to Appian’s integration capabilities. Appian’s documentation emphasizes using the API’s native format (REST here), making this irrelevant.
B. Deploy the API/service into Appian Cloud:Deploying the customer’s API into Appian Cloud is infeasible. Appian Cloud is a managed PaaS environment, not designed to host customer applications or APIs. The API resides in the customer’s self-managed environment, and moving it would require significant architectural changes, violating security and operational boundaries. Appian’s integration strategy focuses on connecting to external systems, not hosting them, ruling this out.
C. Add Appian Cloud’s IP address ranges to the customer network’s allowed IP listing:This approach involves whitelisting Appian Cloud’s IP ranges (available in Appian documentation) in the customer’s firewall to allow direct HTTP/HTTPS requests. However, Appian Cloud’s IPs are dynamic and shared across tenants, making this unreliable for long-term integrations—changes in IP ranges could break connectivity. Appian’s best practices discourage relying on IP whitelisting for cloud-to-on-premises integrations due to this limitation, favoring secure tunnels instead.
D. Set up a VPN tunnel:This is the correct recommendation. A Virtual Private Network (VPN) tunnel establishes a secure, encrypted connection between Appian Cloud and the customer’s self-managed network, allowing Appian to access the internal REST API (https://internal.network/api/api/ping). Appian supports VPNs for cloud-to-on-premises integrations, and this approach ensures reliability, security, and compliance with network policies. The customer’s IT team can configure the VPN, and Appian’s documentation recommends this for such scenarios, especially when dealing with internal endpoints.
Conclusion: Setting up a VPN tunnel (D) is the best recommendation. It enables secure, reliable connectivity from Appian Cloud to the customer’s internal API, aligning with Appian’s integration best practices for cloud-to-on-premises scenarios.
[References: , Appian Documentation: "Integrating Appian Cloud with On-Premises Systems" (VPN and Network Configuration). , Appian Lead Developer Certification: Integration Module (Cloud-to-On-Premises Connectivity). , Appian Best Practices: "Securing Integrations with Legacy Systems" (VPN Recommendations)., , ]
Question # 12
You have an active development team (Team A) building enhancements for an application (App X) and are currently using the TEST environment for User Acceptance Testing (UAT).
A separate operations team (Team B) discovers a critical error in the Production instance of App X that they must remediate. However, Team B does not have a hotfix stream for which to accomplish this. The available environments are DEV, TEST, and PROD.
Which risk mitigation effort should both teams employ to ensure Team A’s capital project is only minorly interrupted, and Team B’s critical fix can be completed and deployed quickly to end users?
A.
Team B must communicate to Team A which component will be addressed in the hotfix to avoid overlap of changes. If overlap exists, the component must be versioned to its PROD state before being remediated and deployed, and then versioned back to its latest development state. If overlap does not exist, the component may be remediated and deployed without any version changes.
B.
Team A must analyze their current codebase in DEV to merge the hotfix changes into their latest enhancements. Team B is then required to wait for the hotfix to follow regular deployment protocols from DEV to the PROD environment.
C.
Team B must address changes in the TEST environment. These changes can then be tested and deployed directly to PROD. Once the deployment is complete, Team B can then communicate their changes to Team A to ensure they are incorporated as part of the next release.
D.
Team B must address the changes directly in PROD. As there is no hotfix stream, and DEV and TEST are being utilized for active development, it is best to avoid a conflict of components. Once Team A has completed their enhancements work, Team B can update DEV and TEST accordingly.
Full Access
Answer:
A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, managing concurrent development and operations (hotfix) activities across limited environments (DEV, TEST, PROD) requires minimizing disruption to Team A’s enhancements while ensuring Team B’s critical fix reaches PROD quickly. The scenario highlights no hotfix stream, active UAT in TEST, and a critical PROD issue, necessitating a strategic approach. Let’s evaluate each option:
A. Team B must communicate to Team A which component will be addressed in the hotfix to avoid overlap of changes. If overlap exists, the component must be versioned to its PROD state before being remediated and deployed, and then versioned back to its latest development state. If overlap does not exist, the component may be remediated and deployed without any version changes:This is the best approach. It ensures collaboration between teams to prevent conflicts, leveraging Appian’s version control (e.g., object versioning in Appian Designer). Team B identifies the critical component, checks for overlap with Team A’s work, and uses versioning to isolate changes. If no overlap exists, the hotfix deploys directly; if overlap occurs, versioning preserves Team A’s work, allowing the hotfix to deploy and then reverting the component for Team A’s continuation. This minimizes interruption to Team A’s UAT, enables rapid PROD deployment, and aligns with Appian’s change management best practices.
B. Team A must analyze their current codebase in DEV to merge the hotfix changes into their latest enhancements. Team B is then required to wait for the hotfix to follow regular deployment protocols from DEV to the PROD environment:This delays Team B’s critical fix, as regular deployment (DEV → TEST → PROD) could take weeks, violating the need for “quick deployment to end users.†It also risks introducing Team A’s untested enhancements into the hotfix, potentially destabilizing PROD. Appian’s documentation discourages mixing development and hotfix workflows, favoring isolated changes for urgent fixes, making this inefficient and risky.
C. Team B must address changes in the TEST environment. These changes can then be tested and deployed directly to PROD. Once the deployment is complete, Team B can then communicate their changes to Team A to ensure they are incorporated as part of the next release:Using TEST for hotfix development disrupts Team A’s UAT, as TEST is already in use for their enhancements. Direct deployment from TEST to PROD skips DEV validation, increasing risk, and doesn’t address overlap with Team A’s work. Appian’s deployment guidelines emphasize separate streams (e.g., hotfix streams) to avoid such conflicts, making this disruptive and unsafe.
D. Team B must address the changes directly in PROD. As there is no hotfix stream, and DEV and TEST are being utilized for active development, it is best to avoid a conflict of components. Once Team A has completed their enhancements work, Team B can update DEV and TEST accordingly:Making changes directly in PROD is highly discouraged in Appian due to lack of testing, version control, and rollback capabilities, risking further instability. This violates Appian’s Production governance and security policies, and delays Team B’s updates until Team A finishes, contradicting the need for a “quick deployment.†Appian’s best practices mandate using lower environments for changes, ruling this out.
Conclusion: Team B communicating with Team A, versioning components if needed, and deploying the hotfix (A) is the risk mitigation effort. It ensures minimal interruption to Team A’s work, rapid PROD deployment for Team B’s fix, and leverages Appian’s versioning for safe, controlled changes—aligning with Lead Developer standards for multi-team coordination.
[References: , Appian Documentation: "Managing Production Hotfixes" (Versioning and Change Management). , Appian Lead Developer Certification: Application Management Module (Hotfix Strategies). , Appian Best Practices: "Concurrent Development and Operations" (Minimizing Risk in Limited Environments)., , ]
Question # 13
For each scenario outlined, match the best tool to use to meet expectations. Each tool will be used once
Note: To change your responses, you may deselected your response by clicking the blank space at the top of the selection list.

Full Access
Answer:
Answer: 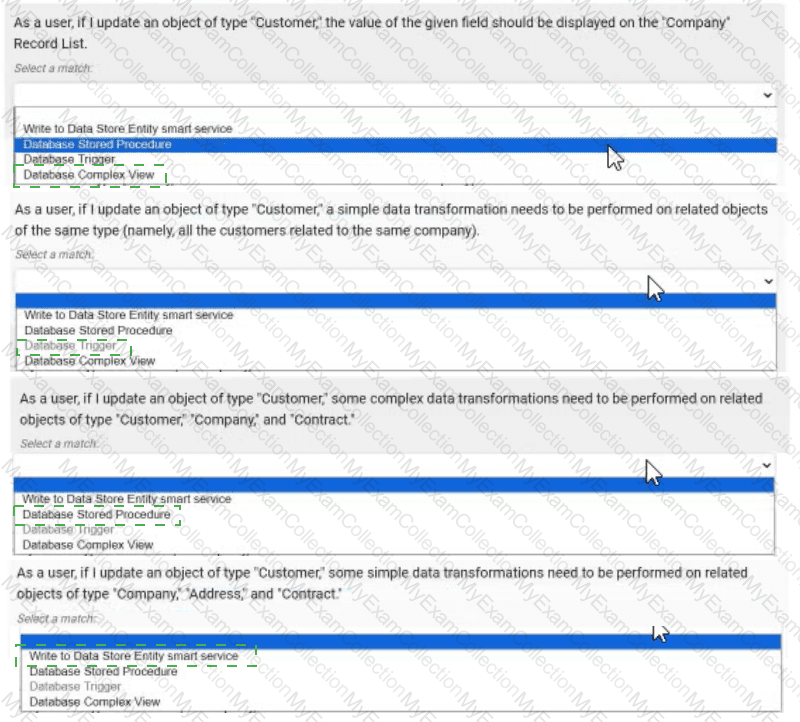
Explanation:
As a user, if I update an object of type "Customer", the value of the given field should be displayed on the "Company" Record List. → Database Complex View
As a user, if I update an object of type "Customer", a simple data transformation needs to be performed on related objects of the same type (namely, all the customers related to the same company). → Database Trigger
As a user, if I update an object of type "Customer", some complex data transformations need to be performed on related objects of type "Customer", "Company", and "Contract". → Database Stored Procedure
As a user, if I update an object of type "Customer", some simple data transformations need to be performed on related objects of type "Company", "Address", and "Contract". → Write to Data Store Entity smart service
Comprehensive and Detailed In-Depth Explanation:
Appian integrates with external databases to handle data updates and transformations, offering various tools depending on the complexity and context of the task. The scenarios involve updating a "Customer" object and triggering actions on related data, requiring careful selection of the best tool. Appian’s Data Integration and Database Management documentation guides these decisions.
As a user, if I update an object of type "Customer", the value of the given field should be displayed on the "Company" Record List → Database Complex View:This scenario requires displaying updated customer data on a "Company" Record List, implying a read-only operation to join or aggregate data across tables. A Database Complex View (e.g., a SQL view combining "Customer" and "Company" tables) is ideal for this. Appian supports complex views to predefine queries that can be used in Record Lists, ensuring the updated field value is reflected without additional processing. This tool is best for read operations and does not involve write logic.
As a user, if I update an object of type "Customer", a simple data transformation needs to be performed on related objects of the same type (namely, all the customers related to the same company) → Database Trigger:This involves a simple transformation (e.g., updating a flag or counter) on related "Customer" records after an update. A Database Trigger, executed automatically on the database side when a "Customer" record is modified, is the best fit. It can perform lightweight SQL updates on related records (e.g., via a company ID join) without Appian process overhead. Appian recommends triggers for simple, database-level automation, especially when transformations are confined to the same table type.
As a user, if I update an object of type "Customer", some complex data transformations need to be performed on related objects of type "Customer", "Company", and "Contract" → Database Stored Procedure:This scenario involves complex transformations across multiple related object types, suggesting multi-step logic (e.g., recalculating totals or updating multiple tables). A Database Stored Procedure allows you to encapsulate this logic in SQL, callable from Appian, offering flexibility for complex operations. Appian supports stored procedures for scenarios requiring transactional integrity and intricate data manipulation across tables, making it the best choice here.
As a user, if I update an object of type "Customer", some simple data transformations need to be performed on related objects of type "Company", "Address", and "Contract" → Write to Data Store Entity smart service:This requires simple transformations on related objects, which can be handled within Appian’s process model. The "Write to Data Store Entity" smart service allows you to update multiple related entities (e.g., "Company", "Address", "Contract") based on the "Customer" update, using Appian’s expression rules for logic. This approach leverages Appian’s process automation, is user-friendly for developers, and is recommended for straightforward updates within the Appian environment.
Matching Rationale:
Each tool is used once, covering the spectrum of database integration options: Database Complex View for read/display, Database Trigger for simple database-side automation, Database Stored Procedure for complex multi-table logic, and Write to Data Store Entity smart service for Appian-managed simple updates.
Appian’s guidelines prioritize using the right tool based on complexity and context, ensuring efficiency and maintainability.
[References: Appian Documentation - Data Integration and Database Management, Appian Process Model Guide - Smart Services, Appian Lead Developer Training - Database Optimization., , , , ]

